2管モデル・3管モデルによる声道の推定のこころみ
声道を単純化した2管モデルと3管モデルで、母音の周波数特性のピークとドロップピークが合うようなモデルの推定を行う。
2管モデル
2管モデルは下図のように、断面積A1の長さL1の管と断面積A2の長さL2の2個の管から構成される、声道を非常に簡略した模型である。
人の声を完全に復元することはできないが、大雑把に特徴を把握するために利用する。
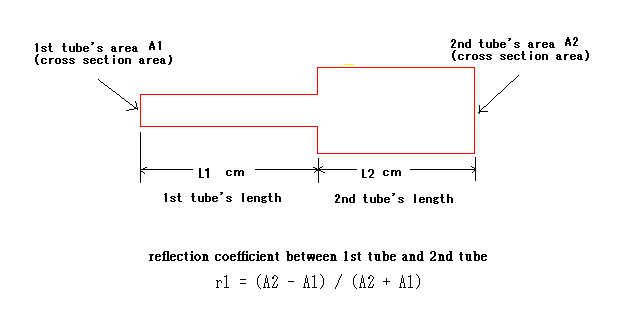
断面積を使って反射係数r1を定義する。
推定の便宜上、2個の断面積A1とA2の代わりに、反射係数r1を使う。
2管モデルの推定は、観測された信号に合うように、長さL1とL2 反射係数r1の3個のパラメーターを求めることである。
3管モデルは、2管モデルに更に1個の管を追加した模型で、推定するパラメーターは
長さL1とL2とL3 反射係数r1とr2 の5個になる。
推定の方法
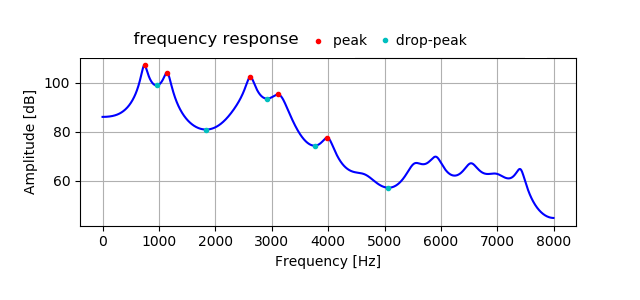
下図は、LPC分析によって求めた母音の音声の周波数特性の例である。
赤い丸がピーク(フォルマント周波数と呼ばれる)、青い丸が局所的なボトム(ここではドロップピークと呼ぶ)を示す。
実際の音声と2管モデルの周波数特性を比較して、
ピークとドロップピークの周波数の値ができるだけ近くなるようなパラメーターを求める。
(評価量としてはフォルマントの強さを使いたかったが、計算が煩雑になるため、代わりにドロップピークを使ってみた。)
一般に、音声から声道の形状を一意に決定するのは難しいとされる。
そこで、ここでは以下の制約条件を付けた。
-
周波数の低い順に各2個のピークとドロップピークを評価量に使う。(3管モデルではそれぞれ各3個使う。)
-
口腔の物理的な開き方を考えて、反射係数の大きさは0.9までとした。(0.9を超える場合はコストにペナルティーを加算した。)
-
2管モデルでは長さL1の方がL2より等しいか大きなものとした。
2管モデルでは全長が同じでL1とL2の値を入れ替えた2つを比較するとピークとドロップピークはほぼ同じ値となることが多い(例外もある)。
下はグリッドサーチの候補の例で(上から順番に周波数が近い、評価コストが低い)、L1とL2を入れ替えたものが順番に並んでいる。
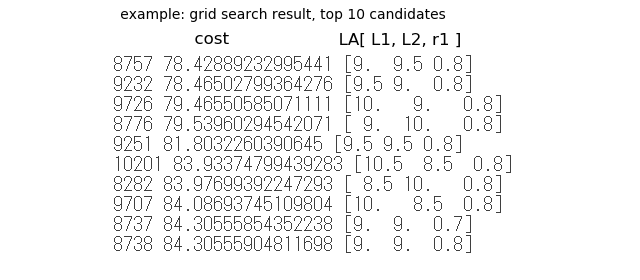
-
母音「お」は3管モデルを使い、3管モデルのr1は0以上(A1よりA2の方が大きい)とした。
推定計算は、あらかじめ計算したデータを利用して代表点を計算するグリッドサーチと、その候補を初期値として詳細なサーチを行う2段階で行った。
推定の例
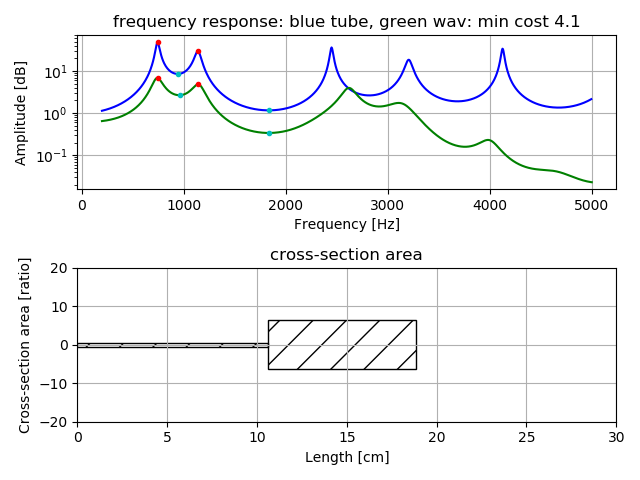
下図は、単独で発声された母音の推定結果である。
上が周波数特性の比較(青が管モデル、緑色が声)で、下が推定された管の長さと断面積の様子を示す。
2管モデルでの「あ」の推定の例
2管モデルでの「い」の推定の例
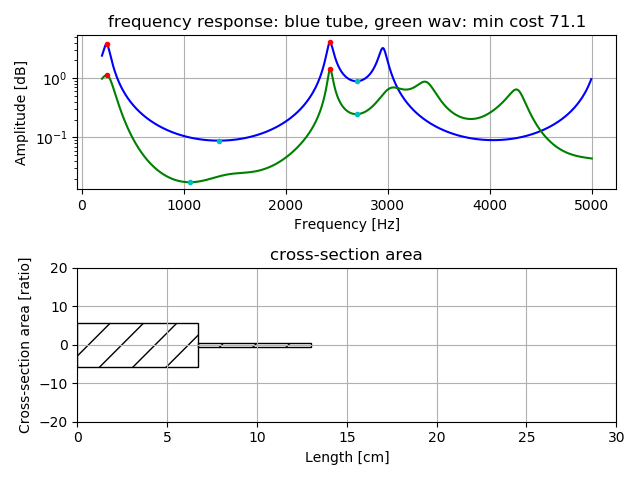
2管モデルでの「う」の推定の例
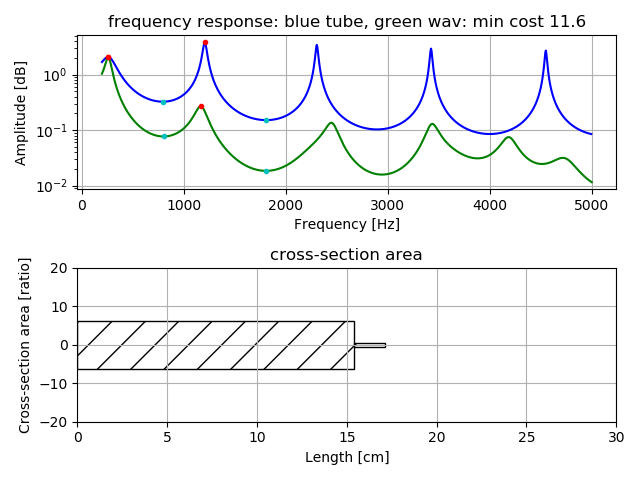
2管モデルでの「え」の推定の例
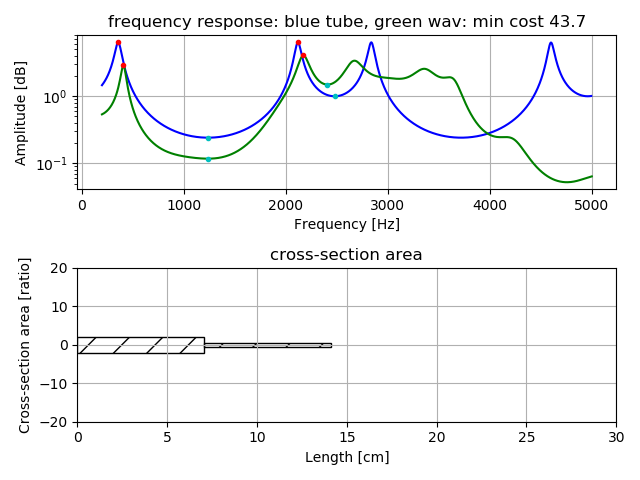
3管モデルでの「お」の推定の例
参考までに、上記で使ったpythonプログラムをおいておきます。 使い方はzipファイルを解凍した中にあるREADME.txtを見てください。
No.1b 2019年3月25日
Home page