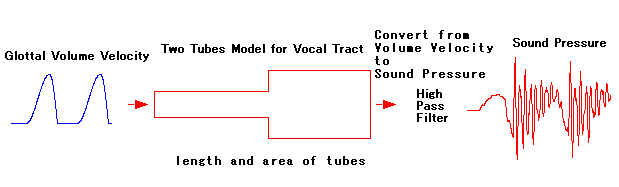
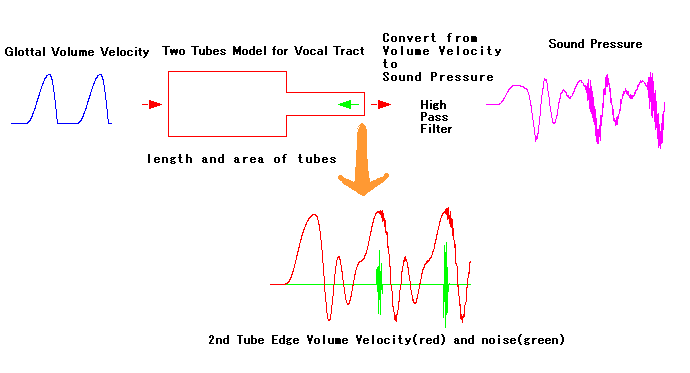
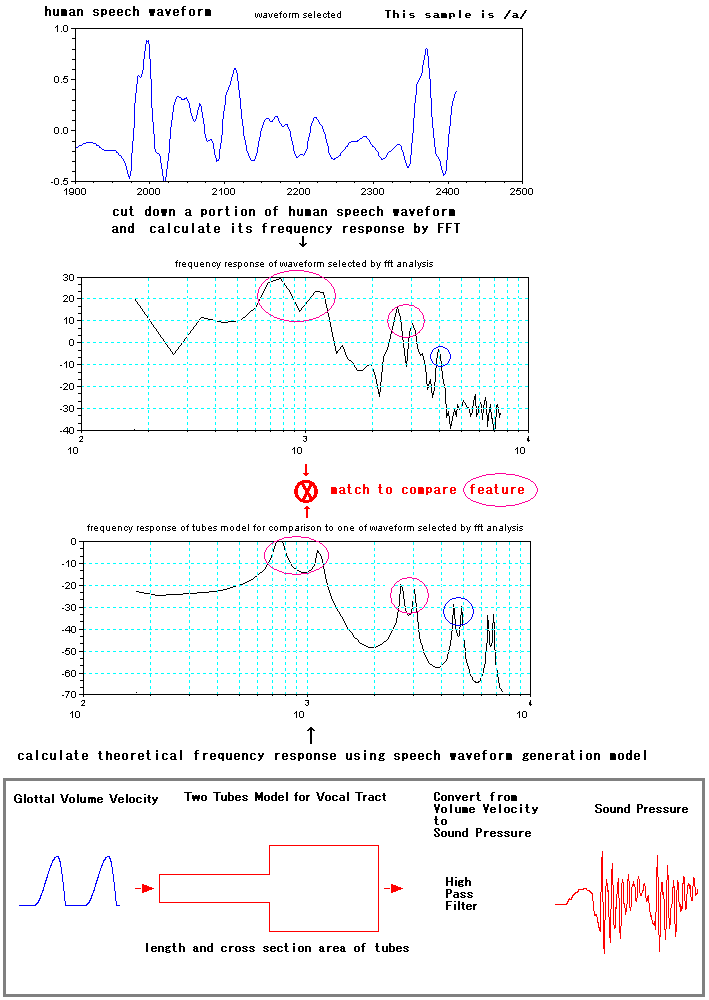
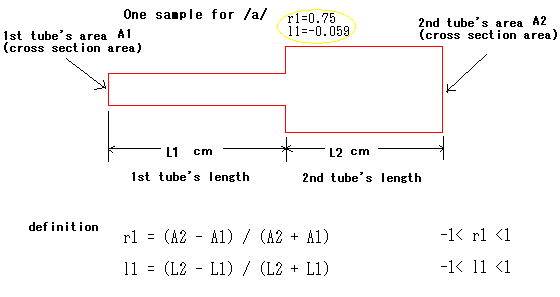To understand the process of human's speech sound generation, a very
simplified model which consists of two tubes and similar signal to air
flow volume velocity at glottal as sound source, is explained in this
chapter.
Simplified speech sound generation process is as follows. To regulate
air flow from lungs at glottal, waveform in the left figure below, of
which
color is blue, is generated as source. And then, the
waveform is led to two tubes which is imitated human vocal
tract. In this, tubes is supposed to be resonator which has
some resonating wave length. In middle figure below,
there
are combined two box of color red. Box width means tube length
and box height means cross section area of tube. At right edge of
combined two box of color red, like human mouth, air flow
volume velocity is radiated out. To pick sound up with microphone
which responses per pressure, air flow volume velocity is
converted to sound pressure, that is right figure waveform red color,
by a very easy way to do high pass filter. Sound pressure
is waveform which imitated to human speech.
Actual human speech generation is more complex and there are many
differences from
this simplified model. However, this simple model, can make sound of
which quality is bad. Three samples, sound like phonetic symbol
/a/,
symbol /ae/, and symbol /ui/, which are made using this two tubes
model are linked ( /a/
/ae/ /ui/ are .wav files)
What can be made using this two tubes model and glottal volume
velocity are limited to three kind
phonetic symbols of /a/, /e/, and /u/.
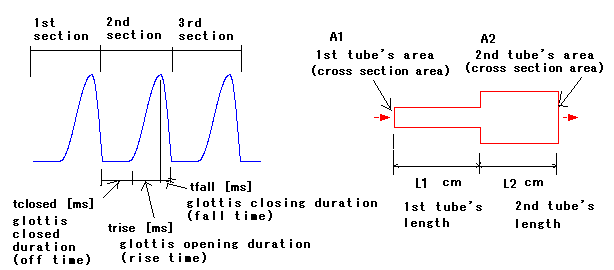
In this model, as a major way, by change of length or cross section
area of tubes, you can adjust sound tone like phonetic
symbol /a/ or /e/. The figure below which consists of two color
red boxes imagines combined two tubes. 1st tube is
length is L1 cm and cross section area is A1 cm 2.
2nd tube is length is L2 cm and cross section area is A2 cm 2.
At left edge of 1st tube, comparing with human, connection with
glottal, glottal regulated air flow leads into 1st tube. Reflection at
each tube edge and air flow movement time of distance of
tube length, cause some modes of resonance. At right edge of 2nd
tube, comparing with human, mouth or lip, variant air flow radiates out
from it.
As glottal regulation, closed duration, opening duration, and closing
duration can be set. Sum of these three duration relates to pitch
period. If pitch period is short, you will hear higher tone sound,
contrariwise period long, lower tone. Repeating close and open of
glottis, air flow volume velocity is uncontinuous, showing blue color
waveform in the left figure above.
Figures below are size sample of two tubes for generation of phonetic
symbol /a/, /e/, and /i/. (Actually, a reason
explained later, /i/ sounds like /u/ in this model.) And also, other
sizes for generation of these symbols exist.
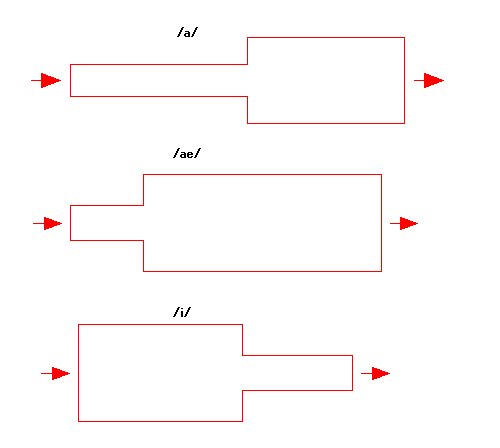
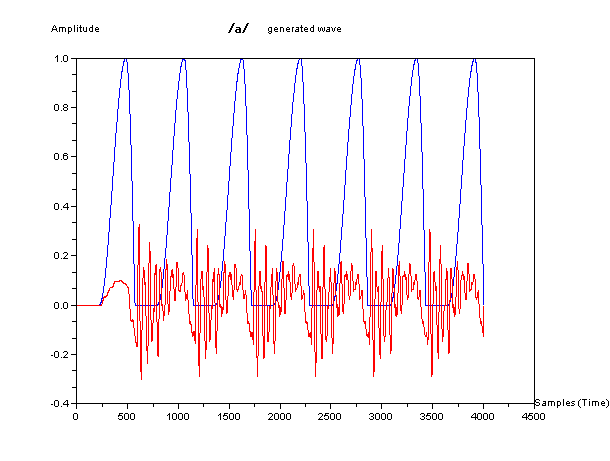
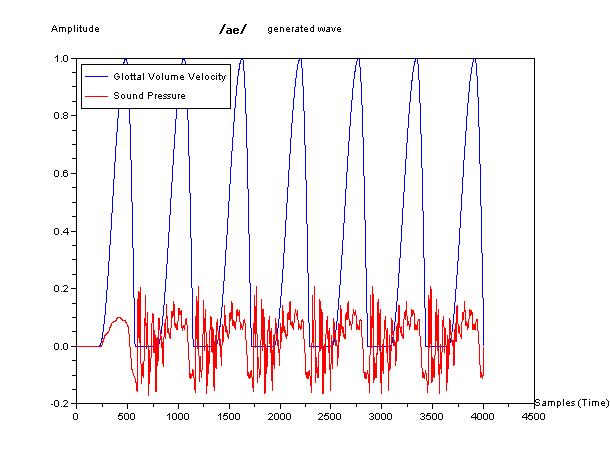
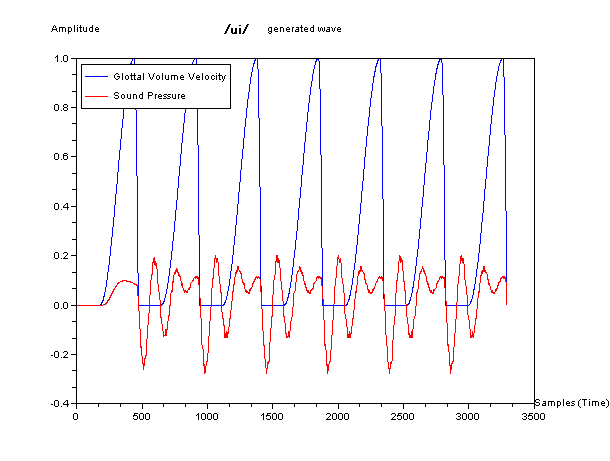
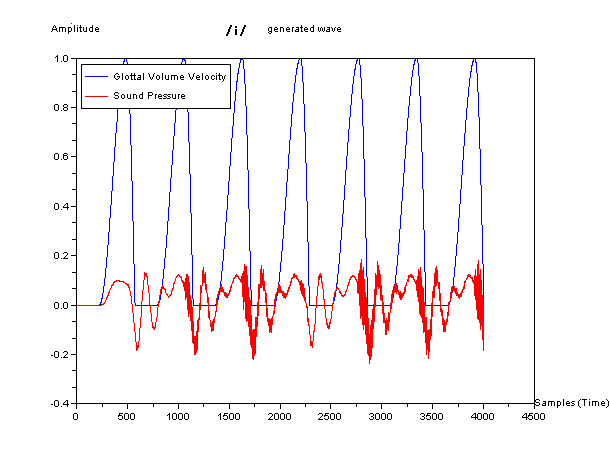
In the figures below, blue waveform is glottal volume velocity as
source and red one is generated sound pressure which imitated to human
speech. They are waveform, sound like phonetic symbol
/a/,
symbol /e/, and symbol /u/.
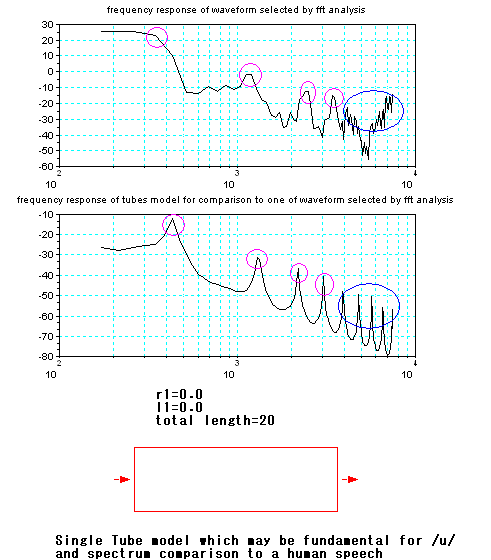
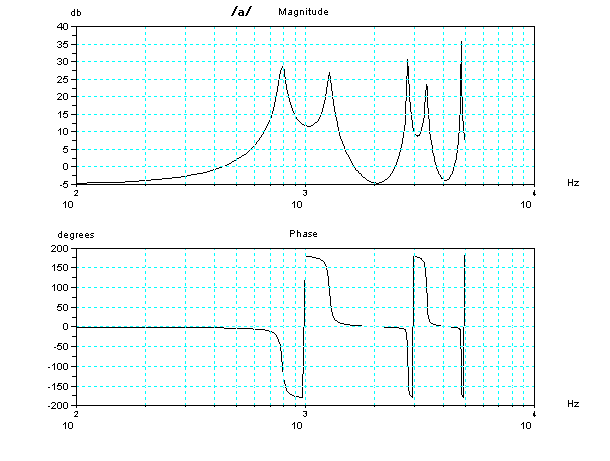
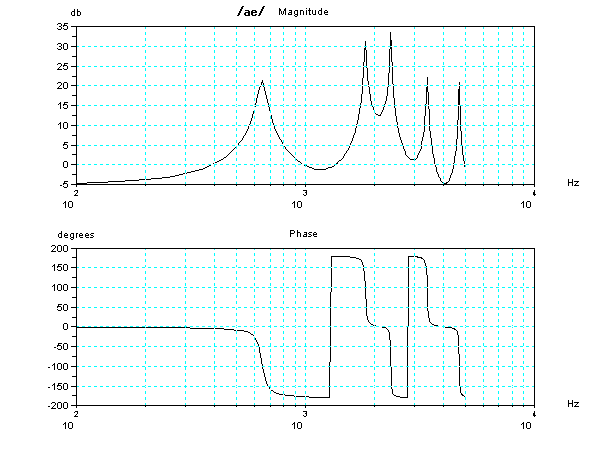
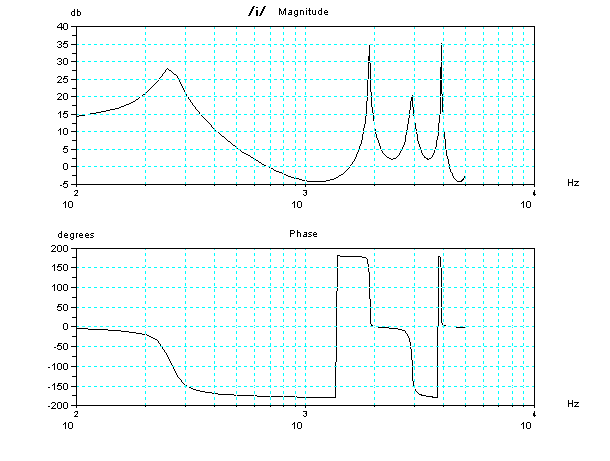
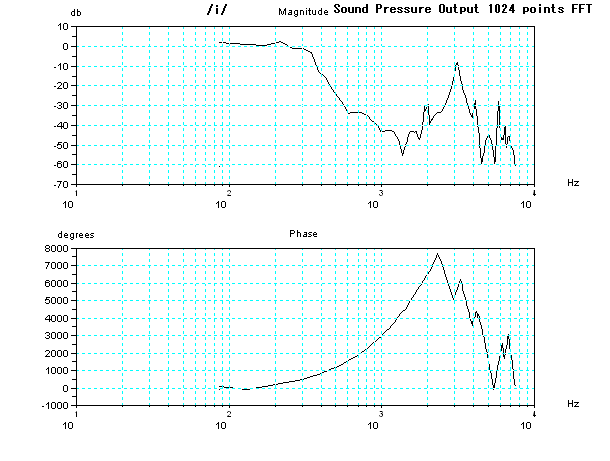
For more details, it may be advanced, the characteristic (Bode
diagram)
of frequency
and phase of these two tubes model for vocal tract are
shown below. In Magnitude (frequency response), there are some peaks
which are capable of resonance. However, to resonate at a peak
frequency, signal including the peak frequency should be introduced as
input. When no signal including the peak frequency, no resonance, it's
as same as the peak doesn't exist. Feature of sound of phonetic
symbol /i/ is to add almost around 2 kHz or more signal to a sound of
phonetic symbol /u/. In this two tubes model and glottal volume
velocity, although the size is suited for /i/, due to lack of the
signal as input, it becomes sound just like phonetic symbol /u/.
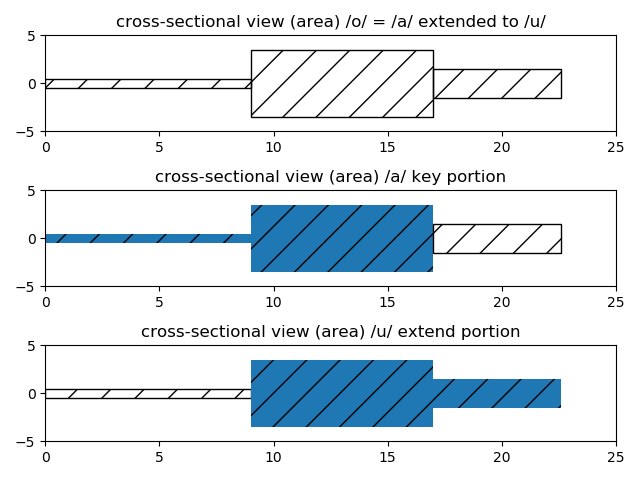
To generation of phonetic symbol /o/, only two tubes is not enough. So,
in next chapter, three tubes models will be explained.
Generation of phonetic symbol /o/ is basing on sound of phonetic symbol /a/
and extended to effect of phonetic symbol /u/. (this is a hypothesis.)
Following figure shows how to extend from /a/ to /u/.
There are three portions, that is three tubes.
Two tubes, source side (left side), corresponds to /a/.
Besides, another two tubes, output side (right side), corresponds to /u/.
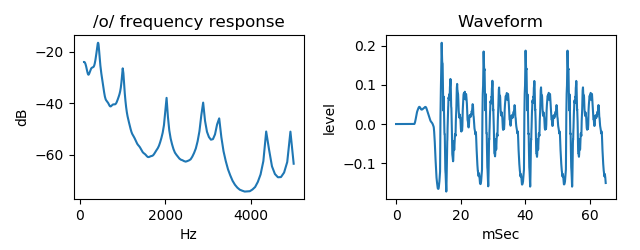
And next figure shows frequency response and generated waveform by this three tube model.
This is generated wav sample of phonetic symbol /o/.
For reference, there is Python program to compute tube model by Python.
Please see README.txt about usage.
Due to lack of the signal of almost around 2 KHz or more, the sound of
phonetic symbol /i/ which is made using two tubes model and glottal
volume velocity becomes like sound of phonetic symbol /u/ in
chapter 1.
So, as source for the signal of almost around 2 KHz or more, to add
noise source which turbulent flow at mouth nearly closed causes to
two tubes model, and generates sound of phonetic symbol /i/ from
glottal volume velocity and noise.
When air flows in narrow space and the velocity of air is over than
certain value, turbulent flow occurs and it makes noise. In this, it's
supposed to be limited frequency band noise signal. In figure
above, red color waveform shows volume velocity of 2nd tube right edge,
that is exit or mouth. When the volume velocity increase and be over
than certain value, noise signal occurs like green color waveform in
the figure. (In the figure, around peak of volume velocity, noise
occurs.) This noise leads to inside, that is to vocal tract.
Result is violet color waveform in the figure. It is waveform including
noise which is almost around 2 KHz or more. A sample sound of
phonetic symbol /i/ which is made using two tubes model from glottal
volume velocity and limited frequency band noise is linked. ( /i/
is a .wav file)
As source noise, band noise of limited frequency about 2 kHz or more is
used. Since already known what is lack to generate waveform of
phonetic symbol /i/, it may be slightly unfair to use
the lack noise.
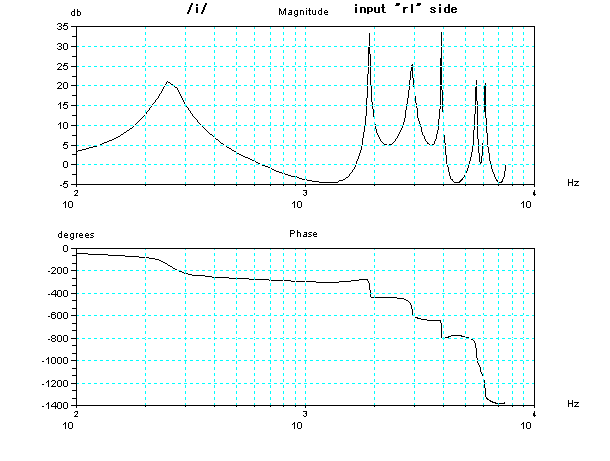
As a reference, the characteristic (Bode diagram) of frequency
and phase of which input is from noise source (rl side) is
shown below. It is almost same as the
characteristic
of two tubes model and glottal volume velocity of /i/.
And also, result of the frequency analysis by FFT (Fast Fourier
transform) of the generated sound pressure is shown below.
For reference, there is Python program to compute tube model with noise mix by Python.
Please see README.txt about usage.
other reference program:
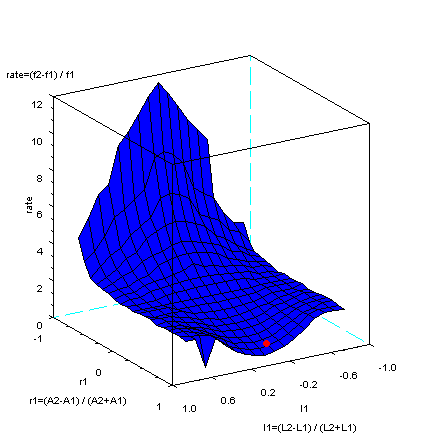
In tube model, length and cross section area are variables that defines
a mathematics space about something physical value. In this, as a
subject, relationship of top two peak waveform is considered.
And, the position of phonetic symbol /a/ which is made by two
tubes model and glottal volume velocity in the space will be shown.
The figure below is one sample size for phonetic symbol /a/. Two
parameters, r1 and l1, which are defined in figure below are
introduced. r1 means relationship of tube area. l1 means relationship
of tube length. As you can image like a trumpet, r1 is closer to
one, that is head more open, sound volume is bigger. And,
if l1 equals zero under certain r1, frequency ratio of top two
peak waveform, that is nearness, is most bottom. In this
sample size for phonetic symbol /a/, l1 is -0.059 (close to zero)
and r1 is 0.75 .
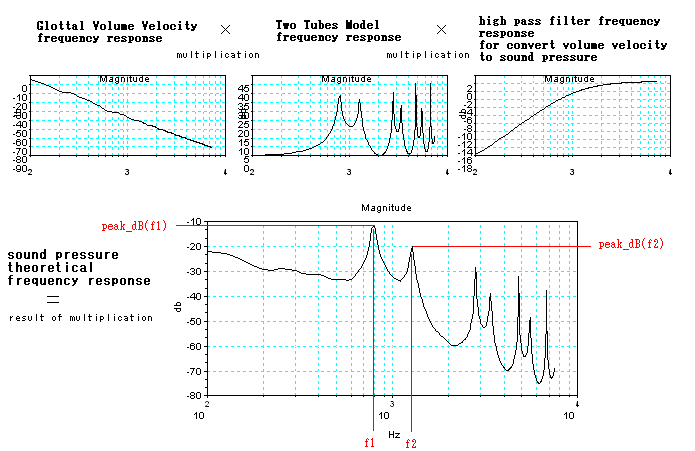
The figure below illustrates the way to calculate sound pressure
theoretical frequency response and what f1 and f2 means.
In figures below, mark of red circle is the position of phonetic
symbol /a/ in space. In this size example for phonetic
symbol /a/ , the position is allocated around where
f1 and f2 are most near in space. And the position is also around
maximum strength (dB) of two peaks average, in the following
condition.
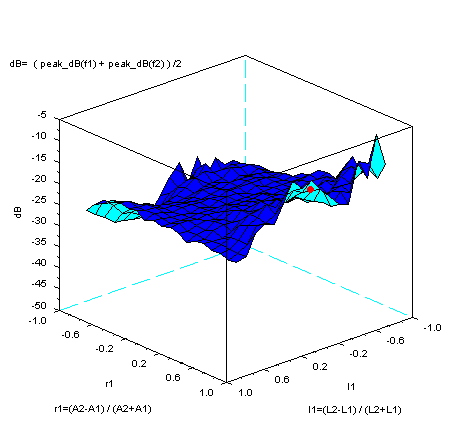
The condition is that total length of two tubes is 17 cm and total
cross
section area of two tubes is
10cm2. Calculation was done of r1 range is from
r1=-0.9 to r1=0.9 step 0.1. and l1 range is from
l1=-0.8 to l1=0.8 step 0.1.
Thinking apply speech waveform
generation model as one of inner structure to speech recognition,
frequency response of
actual human speech waveform and one by two tubes speech
waveform
generation model are compared showing figures below. This sample
is for phonetic symbol /a/. Some
common features, which are marked by purple color
circle, are found in both frequency response figure .
In this time, to make frequency response by speech waveform generation
mode similar to one of actual human speech, 6 parameters,
total tubes length, l1, r1, high pass filter cut off frequency fc,
glottal volume velocity trise and tfall, are adjustable.
Most adjustment are of total tubes length and r1. Total
tubes length changes frequency value of f1 and f2,
besides r1 influences ratio. Since this speech is one part of
phonetic symbol /a/, l1 is initialized zero as ideal value
for phonetic symbol /a/. Others parameter, fc, trise, and tfall
may change envelop-curve of frequency response. In above sample
figure, total tubes length is 18.5cm2,r1 is 0.8, l1 is
0, fc is
1000Hz, trise is 6ms, and tfall is 0.7ms. These six parameters are
classified as follows.
1 individual depended parameter
total tubes length, that is physically, the length from glottal
to mouth.( but this comment has something wrong.)
2 phonetic parameters
l1 and r1
3 sound transmit parameter
fc
4 other parameters
trise and tfall
If the principle of human phonetic sound production is
understood, speech recognition may be possible.
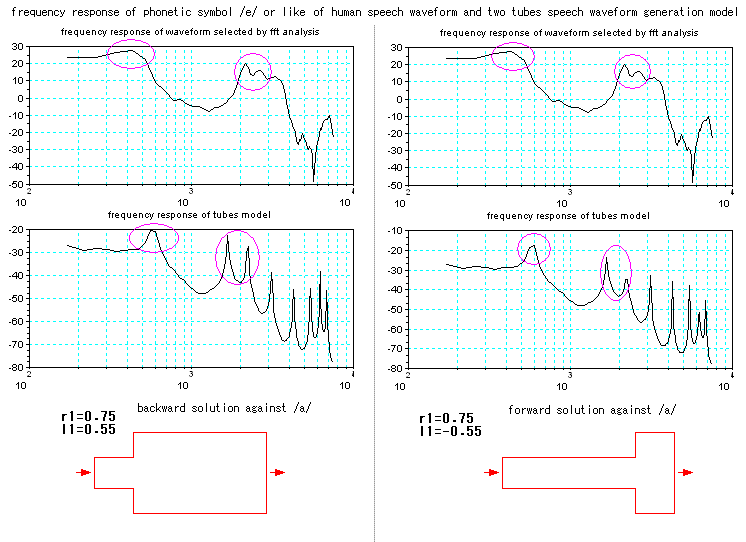
About phonetic symbol /e/ or like it.
Figures below are frequency response of
actual human speech waveform and one by two tubes speech
waveform
generation model. In case of vowel
/a/ showing above, in higher frequency range,
harmonic waves of the two waves
appear as closely and cooperative as same as fundamental ones. Phonetic
symbol /e/ or like it, difference from phonetic symbol /a/, there
is only just one peak in lower frequency range beside
in higher frequency range pair of waves are as closely and
cooperative, showing marked by purple color
circles in the figure below. Maybe "there waves are closely and
cooperative" are essential.
In two tubes model, there are two kinds of solution of r1 and l1
that matches the condition. In the figure below, difference from
solution right to solution left is sign of l1. Supposing that l1
means the location where tongue is curved in mouth,
in case of /a/, l1 which is round zero is center, that is the
location where tongue is curved in mouth is center in
mouth, in case
of solution left, l1 which is 0.55, is the location is
backward against one of /a/, and in case of solution right, l1
which is -0.55, is the location forward against one of /a/.
Although phonetic sound quality is not enough, samples of
backward solution and forward solution are linked ( backward and forward
are .wav files) as reference.
However, phonetic symbol /u/ differs from
/a/ and /e/ of which feature is closely and cooperative pair of waves.
Sound of /u/ may be understood, fundamentally, as simple transit
effect like single tube model shown in the figure below,
and its modifications according actual state.
Home page
No.9, 2 February 2008
21 February 2019