Fricative voice /sa/ sound waveform generation by two tubes model and noise source
This is an experiment to generate fricative voice /sa/ sound by two tubes model and noise source instead of turbulent sound.
The sound consists of two parts, that are preceding noise sound and following vowel sound.
The noise sound of voice /sa/ is turbulent sound which has high frequency components and is sustainable compared to
one of voice /ka/ sound that is impulsive short-lived.
Generation of following vowel sound
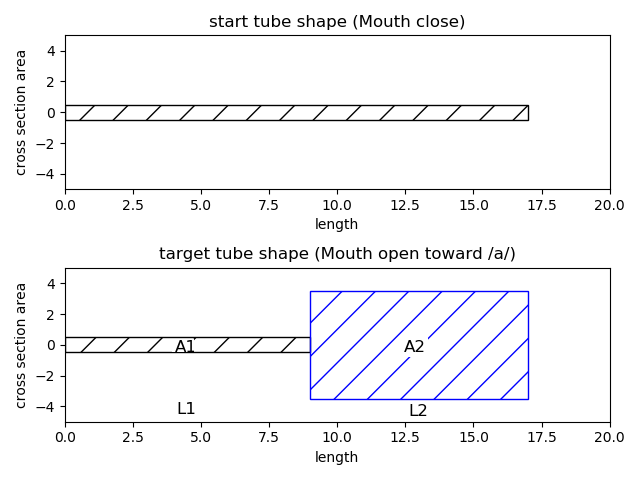
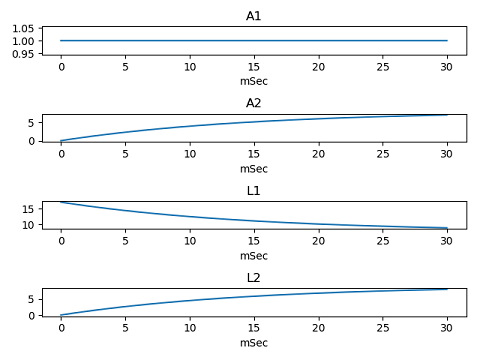
Generation uses two tubes model that can vary cross section area and tube length every time step. They are varied from mouth close state to vowel /a/ state as following figures.
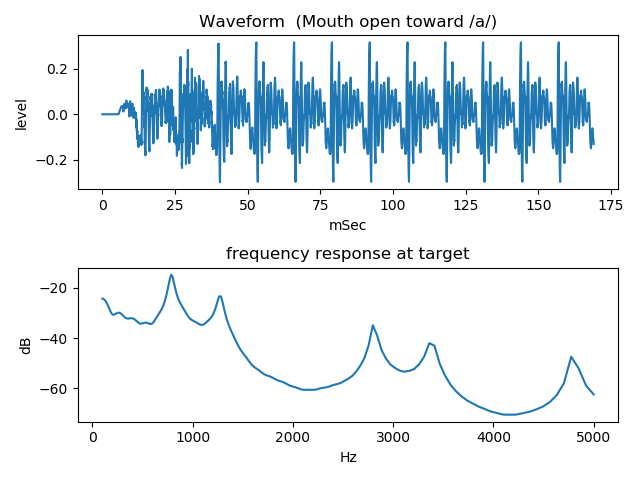
Next figure shows generated waveform and sounds (wav file)
Generation of preceding noise sound
There are two considerations about noise source instead of turbulent sound,
air flow velocity rises up by inspired breath
resonance effects by turbulent sound source and around it
(refer to Consonants perception)
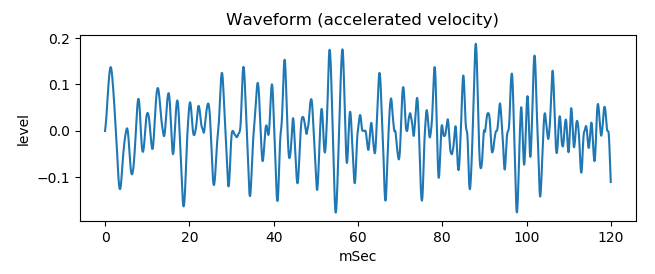
Perlin noise method can generate noise sound whose cycle becomes shorter with time (the frequency rises) to simulate air flow velocity rise.
For example, rising velocity is essential to reproduce the breathtaking feeling of /fu/ sound.
Following figure is generated waveform that cycle becomes shorter with time. It sounds (wav file).
Turbulence sound at teeth is expected to have high frequency components.
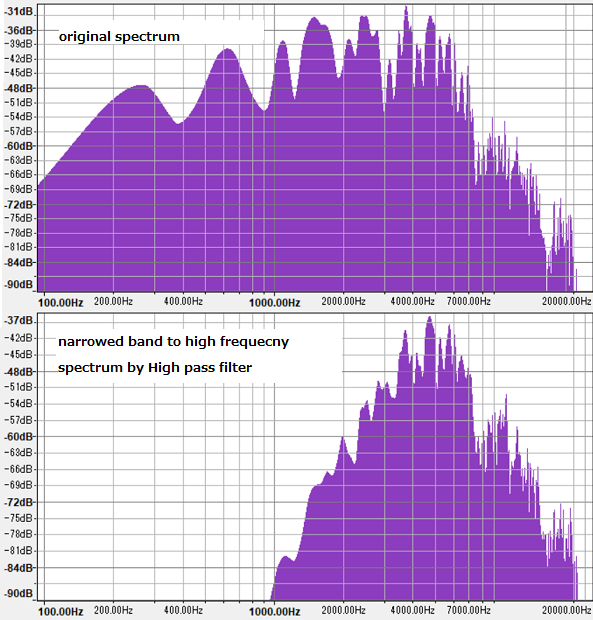
Since this perlin noise contains many low frequency components, High pass filter is applied to narrow frequency band to high frequency.
Following figure is a comparison of original spectrum including low frequency components and narrowed band spectrum to high frequency, using Audacity Plot Spectrum.
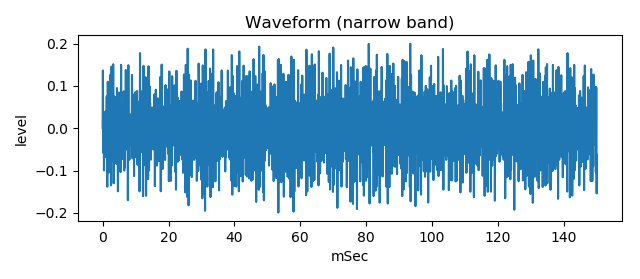
Following figure is generated waveform of the narrowed band spectrum. It sounds (wav file).
And next step is to apply resonance effect to the noise by use two tubes model.
This is done by use the noise as input source of two tubes model.
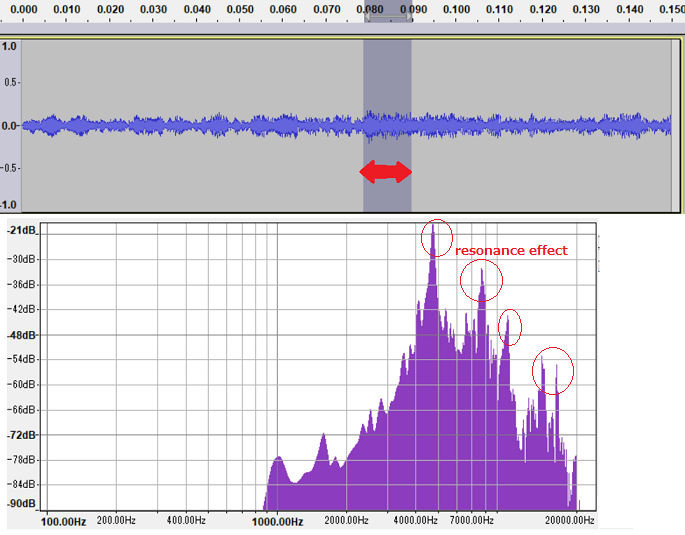
Following figure is the waveform which is applied resonance effect and a local spectrum at arrow location.
(Spectrum varies with location). Resonance effect causes peaks in red circle.
This waveform (wav file) sounds a little similar to /su/ sound.
Combination preceding noise sound and following vowel sound
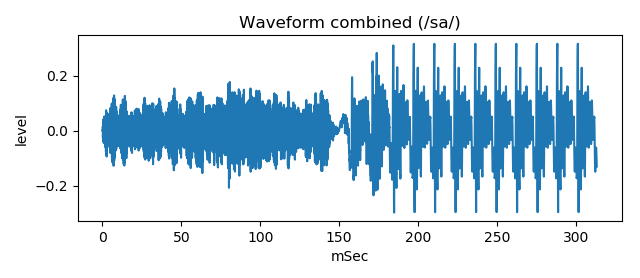
Finally, the noise sound and vowel sound is combined, smoothing connection edge.
This waveform (wav file) sounds similar to voice /sa/ sound.
For reference, there is Python program to compute above waveforms by Python. Please see README.txt in the zip file about usage.
No.2, 4 February 2019