Plosive voice /ga/ /ka/ sound waveform generation by pseudo blast impulse, noise source, and two tubes model
This is an experiment to generate plosive voice /ga/ /ka/ sound by pseudo blast impulse waveform, noise source instead of turbulent sound, and two tubes model with loss.
In this method, the sound will be generated from resonance effected mixed sound of pseudo blast impulse and noise, and following vowel sound portion controlling glottal sound source.
Generation of pseudo blast impulse waveform
It is said that waveform generated by blast phenomenon has a characteristic of 1/f frequency response .
If it uses 1/f frequency response as it is, resonance effect is difficult to be appear, since the amplitude becomes too small even in low frequency component.
For that reason, generation uses frequency response from DC to a certain frequency is flat and after that closes to 1/f.
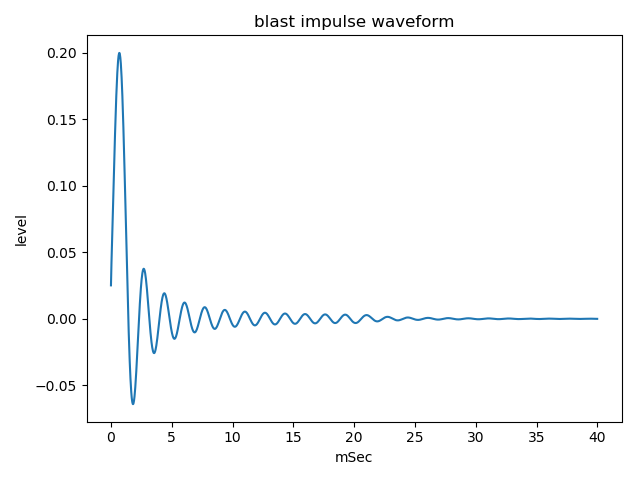
Following figures is the waveform of generated pseudo blast impulse waveform by Hilbert transform and minimum phase condition. It sounds (wav file)
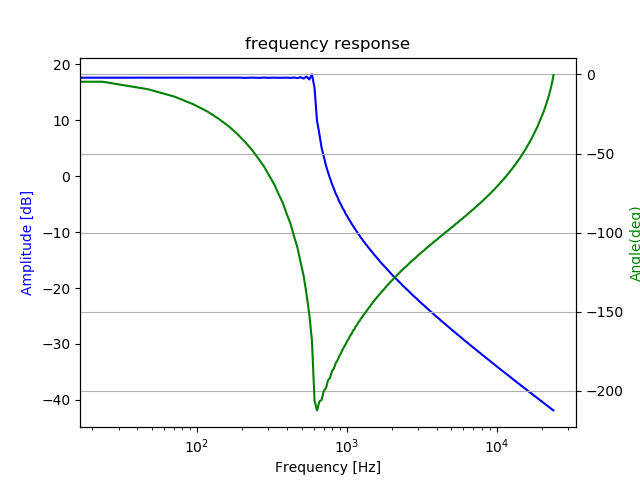
Next figure shows frequency response.
Generation of noise sound
Perlin noise method is used as noise source instead of turbulent sound. This is same as fricative voice /sa/ sound waveform generation.
The difference from fricative is that noise frequency is low.
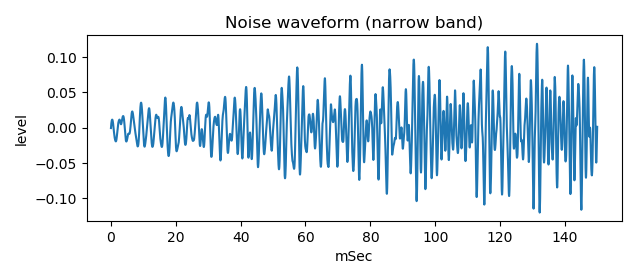
Following figure is the waveform of generated noise sound. It sounds (wav file)
Mix the noise sound with pseudo blast impulse waveform
Assuming that a blast and subsequent breath will generate a turbulent sound, mix the noise sound with pseudo blast impulse waveform.
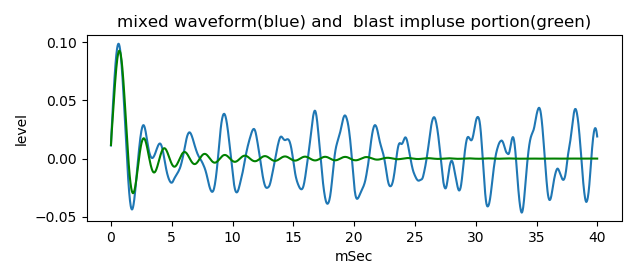
Following figure is the waveform of the mixed. It sounds (wav file)
Apply resonance effect
By use two tubes model of which input source is the mixed waveform, it applies resonance effect to the mixed sound.
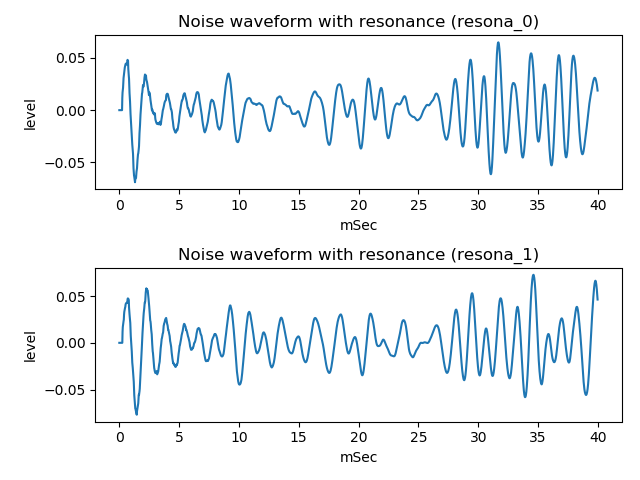
Following figure is two waveforms which is applied different resonance effect. First one sounds (wav file)
Generation of following vowel sound
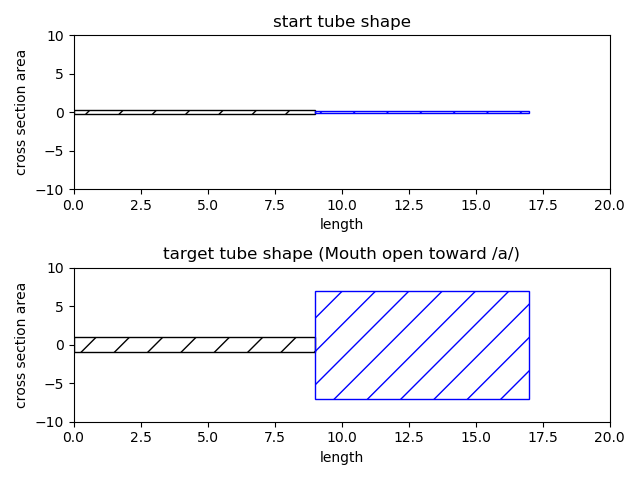
To generate vowel sound, it uses two tubes model that can vary cross section area and tube length every time step.
They are varied from one neutral state to vowel /a/ state as following figures.
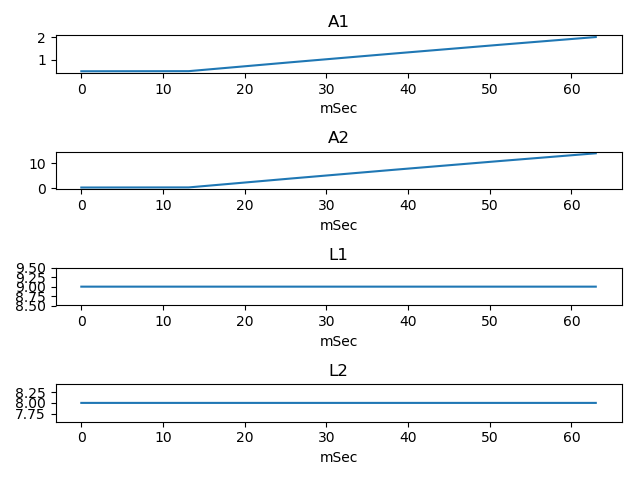
Following figure shows cross section area and tube length per time. They start to vary after one pitch duration, of which initial reflection is not yet seen.
Voiced sound and unvoiced sound
Voiced sound or unvoiced sound, also depends on the strength of resonance effect.
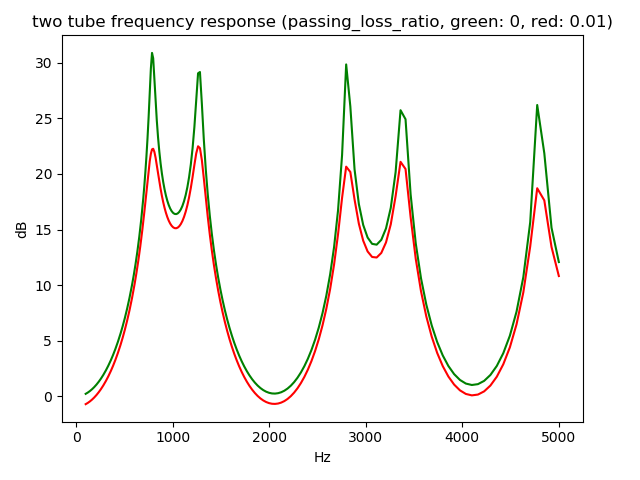
Loss passing tube defined as follows is used to control resonance effect.
For example, loss adjustment can vary peak strength of resonance, resonance effect, as shown below two tubes model frequency response comparison for loss.
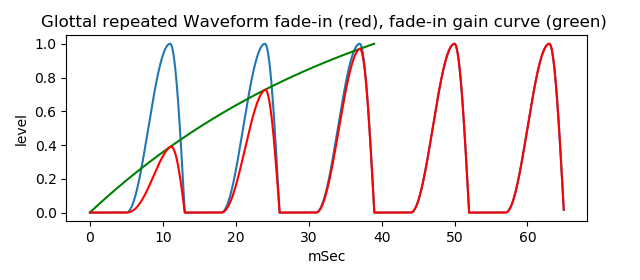
And also, glottal sound source is controlled to start slowly, fade-in, like red waveform in following figure.
As following vowel portion to combine, two waveforms are prepared.
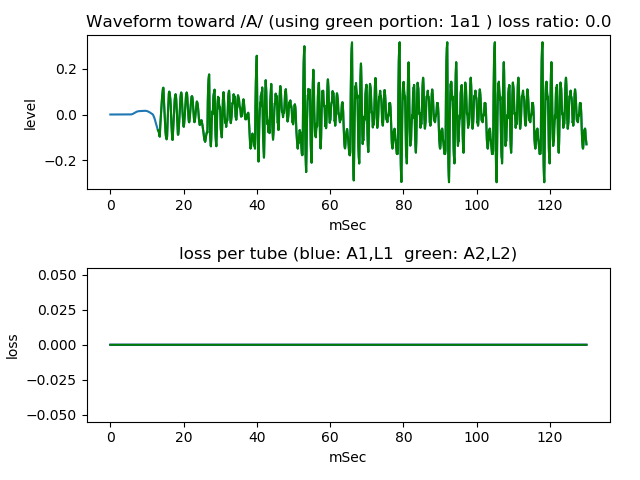
One of which resonance effect is strong (no loss) is for voiced sound.
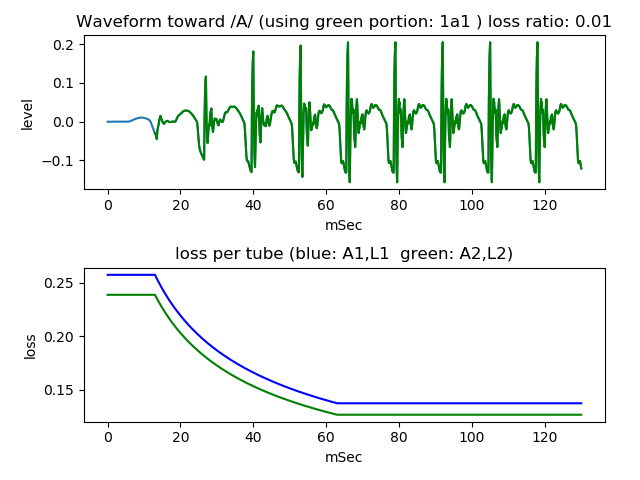
Another of which resonance effect is weak is for unvoiced sound.
Following figure is the waveform of which resonance effect is strong (no loss). It sounds (wav file).
And next figure is the waveform of which resonance effect is weak. It sounds (wav file).
For combination, waveform which is removed initial one pitch duration, green portion in the figure, is used.
Combination waveforms
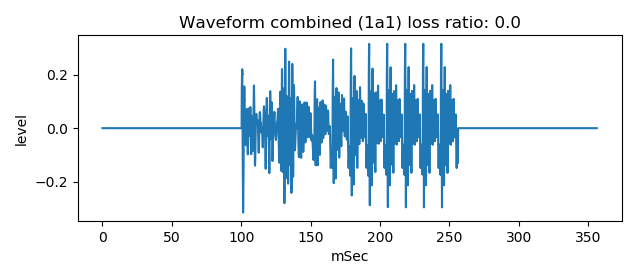
Finally, the mixed waveform of pseudo blast impulse and noise, which has resonance effect, is combined with following vowel portion, smoothing connection edge.
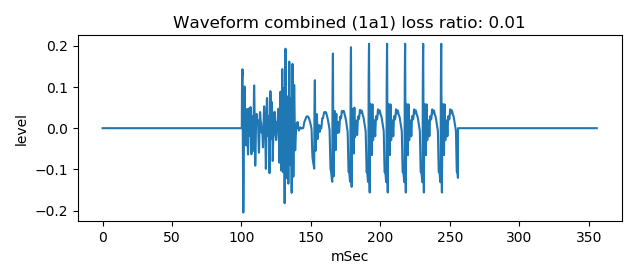
Following figure is the waveform of combination with following vowel portion of which resonance effect is strong (no loss).
This waveform (wav file) sounds similar to voice /ga/ sound.
Next figure is the waveform of combination with following vowel portion of which resonance effect is weak.
This waveform (wav file) becomes unvoiced sound.
For reference, there is Python program to compute above waveforms by Python. Please see README.txt in the zip file about usage.
No.2b, 18 February 2019