
|
A Study of Speech Recognition based on Inner
Structure
by
Isi Shun

|

|
This page describes a concept of voice recognition regarding phoneme as composite signal.
<
Message from author >
Study of speech science has been
some prospered and its application is some useful for us.
However, i feel that we still lack
for
understanding about human speech recognition principle.
Not process superficial feature,
but discover hidden mechanism in diversity of speech signal wave, that
is so many shapes but one common meaning, is necessary.
So, i made this web page hoping
of proper speech recognition principle study and its development.
<
Speech Recognition Based On Inner Structure >
The mechanism, generative structure, exists inside of the observed
feature of speech signal. Let's call it inner structure.
The nature of speech signal is diversity, that is many forms but one
common phonetic meaning.
Every inner structure are grouped due to vocal organs movement
conditions, conditions of mouth open range and tongue turn range, and
there is certain freedom in generative mechanism that
causes diversity of speech signal.
Speech recognition based on inner structure is a pattern
recognition method to
estimate which the inner structure of the spoken phoneme.
(1)Due to the speech organs structure and its movement limits, and
requirement of utterance is discriminative, significant sound position
of organs structure, place of articulation, must lead to at the end or neutral. Therefore, combination of
position correspond to phoneme is limited to some.
(2)Due to restriction by relation in structure,
feature parameters of speech ( for example, formant frequency set)
are not independent each other. They can not take
value independently. If first formant and second formant
are known, third formant will be able to be predicted
by generation mechanism calculation of the structure.
To apply like this way is a kind of structure fitting.
(3)Everybody has different organ and does not speak as utter same
as others , however speech itself is understandable for
everyone.
This will lead the concept of relative valuation (like
concept of frequency ratio) and starting point (a key).
The recognition
method is to find that the experiment signal contains the sound generated
by the structure position.
Pattern recognition based on inner structure is a hypothesis under
study, is not
completed yet. Human speech wave is varying, due to
individual vocal cords, comfortable condition, and
surrounding environment. And there is no fixed reference value in
it. As elements of speech wave will be defined by relationship
each other, solution for this pattern recognition should be
optimization to fit elements to expectant structure.
apply speech waveform
generation model as one of inner structure to speech recognition
The table below shows one consideration about the kind which can be
generated by human mouth structure limitation.
Determine classification of what phoneme, by estimate following
factors, and integrate them, and judgment
|
estimated factors |
kind |
Reason why the feature exists.
Or, principle to decide it |
| resonance
parameters |
r1,l1 |
/a/ |
principle of maximum radiation
from mouth by using two waves |
| /e/ |
stationary point by using one
wave and two waves |
| /u/,/i/ |
other |
| r1,l1,r2,l2 |
/o/ |
Extend method,
from 2 tubes model to 3 tubes model. 1st and 2nd tube
follows principle of maximum radiation, 2nd and 3rd follows like /u/.
|
| rl |
rate of resonance effect in
mouth |
|
| noise |
nature |
constant,burst |
turbulent boundary |
| frequency range |
/i/,/s/,/t/,start mark of /r/ |
Are they determine by physical
of human vocal organs ? |
| superpose |
sonant( more disturb
origin),independent |
classification of noise
superpose method |
| effective
duration |
survival rate |
/t/,/p/ |
Is the unit to judge a pitch
duration ? |
| break |
/p/ |
same as above ? |
| suppressed |
portion to be suppressed |
/m/,/n/,/N(nn)/ |
Compare with following vowel ?
To increase kind by using nose effect |
| tune |
controlled pitch |
stable, rise, fall |
any state will be composed from
these 3 states. To increase kind by
using tune. |
The
content in the table above is still hypothesis. It is an idea to
recognize human speech sound.
And transition between phonemes will take as short as possible. Due to
both this transition principle and physical limitation
of vocal organs movement, transfer way from phoneme to one should
be restricted.
Both estimation of vocal organ structure as effect and estimation of
vocal chord structure as sound source should be done to
phoneme discrimination.
No.6, 30 June 2009
Addition, 16 June 2013
Addition, 18 April 2014
Addition, 5 May 2014
Addition, 30 May 2014
Addition, 17 December 2014
Modification, 7 November 2018
How to find structure hidden in sound signal
In general, observed sound signal is not similar to prediction
from the structure. So, identification method based on error, whole
error, between observed signal and prediction from the structure,
will not work well.
Getting knowledge of characters which consist of two or more
relation, and examine if there is the character in some portion
of observed. This procedure will be done step by step,
through trial and error.
Although it is not about speech cognizance, to increase understanding of this procedure, there is
An example of structure identification by
rough full search and nonlinear least square method to estimate
parameters of two composite structures in signal
The best way for machine recognition of pattern is logical process, analytical method or recurrence relation , using whole elements at same time. However, such method is not found yet.
No.2, 17 February 2015
Discrimination in mixed sound
Human speech, and also, other sound, which human can recognize, has its
inner structure. For example, inner structure of piano sound, inner
structure of violin and so on. One may can discriminate the
desired sound by detecting the inner structure in mixed sound.
Comments
about features of five
Japanese vowels
In Japanese, vowel /a/ and vowel /u/ are basic.
Vowel /a/ feature is that according to principle of maximum
radiation from mouth by using two waves , radiated waves
from mouth
are put in order as closely and cooperative. (1) In higher frequency range,
harmonic waves of the two waves
appear as closely and cooperative as same as fundamental ones in case
of vowel
/a/. This effect is similar to horn loudspeaker.
Vowel /e/, waves from mouth are adjusted by
tongue that in lower frequency range there is no pair of waves,
just one, beside in higher frequency range,
pair of waves are as closely and
cooperative. (4)
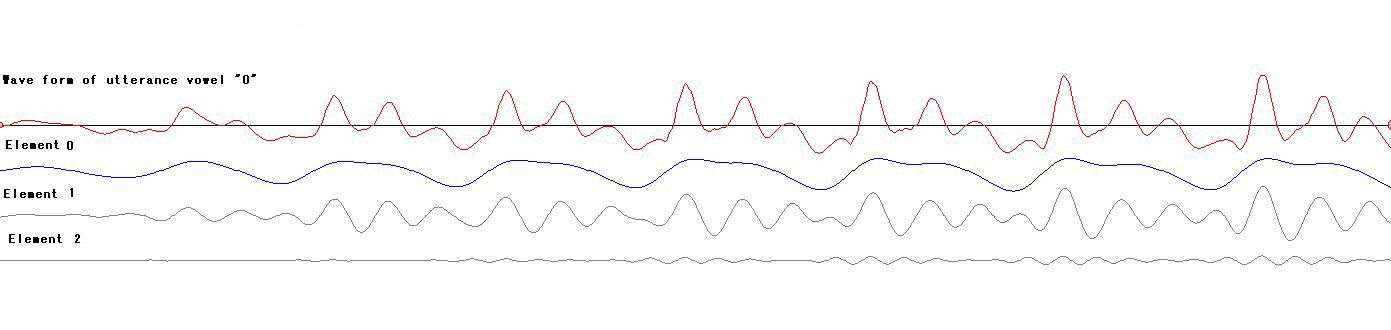
Beside vowel /o/ is basing on vowel /a/
and extended to /u/ . (3)
Vowel /u/ has no color
which means that has no pair of waves which are
closely and cooperative (as a key) , or, if there are, they are not
extreme and
gentle
slope in frequency spectrum. The feature of vowel /u/ is feature
less other than vowel /a/ , /e/, or etc. Since that, many
solutions
exist as
match as vowel /u/.(5)
Vowel /i/ is of vowel /u/ and noisy signals added to it. Its noisy
signals are caused by flow in narrow way out in mouth. This noisy
existence informs of closely mouth utterance. (2)
Attention: These comments are still
hypothesis.
principle of consonant
An
experiment to generate sound
like phoneme by two or three tubes model with digital
filter
No.27, 7 November 2018
Comments
about features of Japanese consonants of /ha/, /sa/, /ka/,
/ta/, /ma/, /na/, /ra/ and /pa/
Besides other languages, japanese language should be recognized
as a pair of consonant and vowel, in short, consonant is
not independent sound. But, principle of consonant may be
similar in every languages.
- /ha/ adopts an suitable noise sound
instead of voiced sound as source for resonance system. The generated
sound is voiceless but it includes resonance feature.
- /sa/ creates higher band noise due to draft
between teeth.
- /ka/ creates irregular burst
 which
is a non linear phenomenon due to strong blow. And it
resonates lightly in mouth.
which
is a non linear phenomenon due to strong blow. And it
resonates lightly in mouth.
- /ta/ has many forms. One is fast rise
with noise due to normal blow.
- /ma/ starts from sound effect, that is erase nature
peak and erase higher frequency band expect two major peaks by nose.
And gradually makes the sound effect less and revitalize
lost peaks.
- /na/ similar effect to /ma/. difference is
initial state of mouth. /ma/ initial is almost of target form state,
beside /na/ is from close tongue state to target form
state.
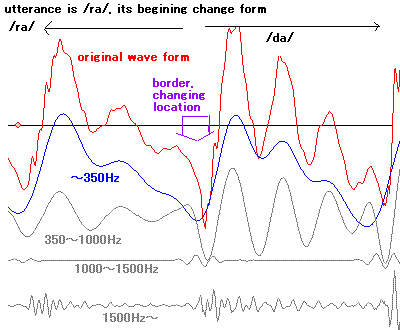
- /ra/ starts from a marked sound when tongue take off
the roof of the mouth (example).
And then, principle of /a/
will be gradually formed through unstable states.
- /pa/ starts reflective sound by starting strong breath flow.
Attention: These comments are still
hypothesis.
An
experiment to generate sound
like phoneme by two or three tubes model with digital
filter
No.5,
23 May
2009
Sound Structure Description
Inner Structure for Pattern
Recognition
For speech recognition
feature, unit of spectrum or unit of cepstrum is not enough to
discriminate speech.
To discriminate, more detailed observation is necessary.
As an experiment, let's study elements of speech signal and their
change of times.
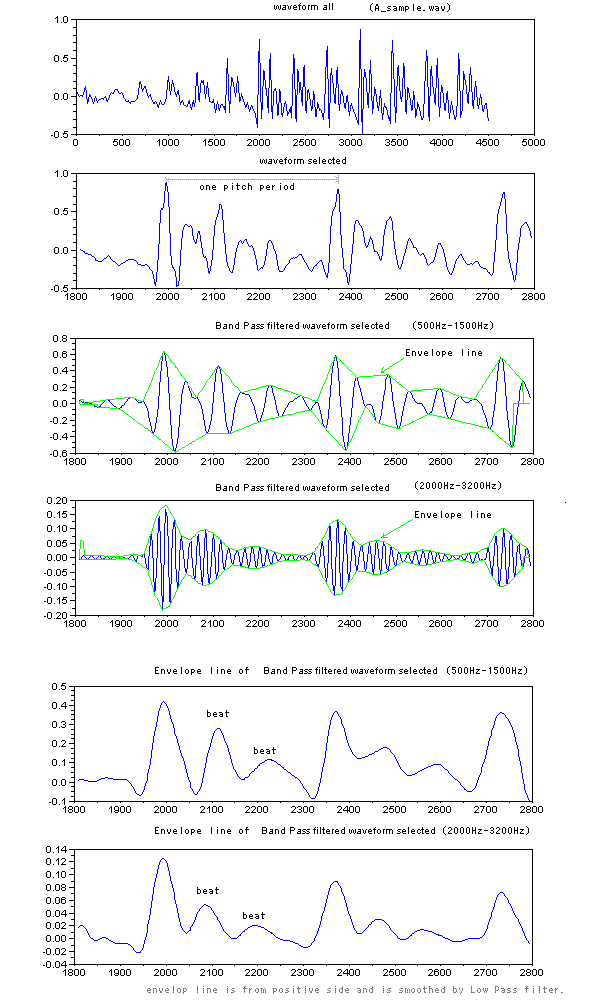
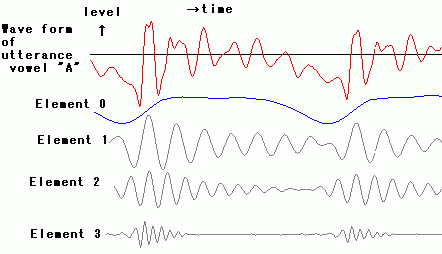
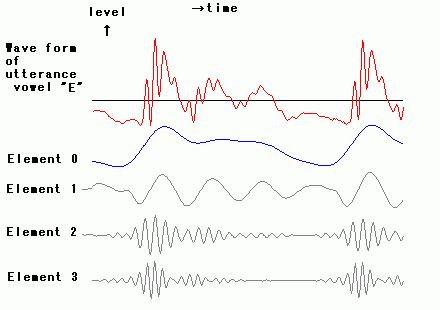
<Analysis of Speech Wave >
Speech signal can be composed of
several elements. The figure right shows elements which are some linear
phase FIR digital filter outputs of speech signal. Frequency band of
linear phase FIR digital filters are manual adapted more
discriminative. In figure right, top red color wave form is original
wave form of one part of utterance japanese vowel "A". Next blue color
wave form and three gray color wave forms are elements of which sum
makes almost original wave form red color. Blue color is mainly caused
by vibration of vocal cords. And gray colors are burst signal in higher
frequency range, which is caused by stress at initial cycle of
vibration of vocal cords. And they are
not simple sin wave.
Besides japanese vowel "A" is composed of set of higher frequency
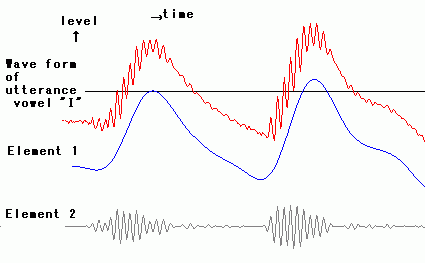
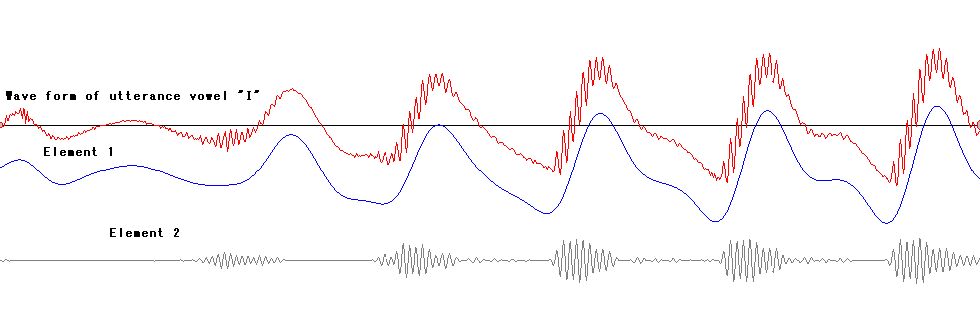
elements, let study next japanese vowel "I". "I" is composed of a
base wave and some waves like noise on the base wave. In figure
right, blue color, element 1, is base and gray color below,
element 2, is high frequency waves on the base. If japanese
vowel "I" without element 2, it's heard as japanese vowel "U."
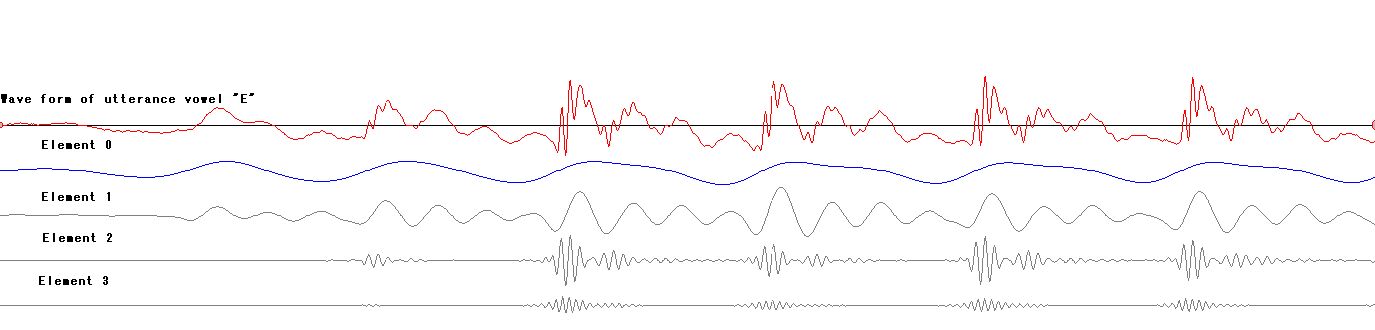
Next is japanese vowel "E." It mainly consists of element 1,
which is heard as "O" when it's solo, and element 2 which
features "E." Element 3 gives effect to be heard as surely "E."
Human discrimination may use dynamic changing portion rather than
stable portion of speech signal. Sometimes, a part speech wave which is
cut out from continuous speech, is heard as other different syllable
from the syllable in the continuous speech. This might be explained by
human discrimination priority to dynamic changing portion rather than
stable ones.
As simple samples, little bit hard to observe, there are initial
dynamic portion of utterance japanese vowel "A",
"I", "U",
"E", and "O".
|
|
Beside utterance japanese vowel "A" makes a set of higher frequency
waves, some kind of utterance makes sound restrained. For example,
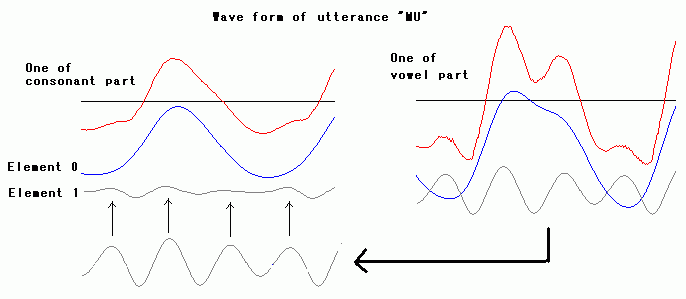
utterance japanese "MU", the figure below is comparison a part of
consonant of "MU" with a part of vowel of "MU." Both have gray color
element of which cycle is same. But, level of gray color element in
consonant is restrained and is very small than one in vowel. In vowel,
with blue color element, gray color element is opened and is well.
As a simple sample, there is utterance japanese "MA."
|
|
Generally, japanese consonant portion is not same,
but is
sometimes modified
due to having reflection of each vowel following the consonant.
Difference from other language
utterance:
In Japanese utterance, independent consonant is rare case.
Usually, consonant links vowel following the consonant and is uttered
as one syllable. Duration of foreigner speaker's japanese
consonant makes sometimes a little strange for us.
|
No.7,
13
May
2007
<Description of Speech Elements >
Let's think about useful way how to describe elements of speech
signal.
This is an example for description of speech elements by XML
(Extensible Markup Language).
It's a description of speech elements for a syllable, japanese
utterance vowel "A."
In XML below,
Element_1_for_A means that it's element 1 of vowel "A."
Element_3_for_A? , mark ? means option which has it or doesn't
have it.
Wave_Unit_Type3+, mark + means that Wave_Unit_Type3 occupies
continuously some times.
<?xml version="1.0"
encoding="UTF-8"?>
<!-- Description of a syllable, japanese utterance vowel
"A" Version 0.02 -->
<!DOCTYPE Independent_Vowel_A [
<!-- Speech wave signal consists of three portions,
generative, stable, and resolvable one. -->
<!ELEMENT Independent_Vowel_A (Generative_Portion,
Stable_Portion, Resolvable_Portion )>
<!-- Description of generative portion -->
<!ELEMENT Generative_Portion (Wave_Unit_Type1,
Wave_Unit_Type2, Wave_Unit_Type3+)>
<!-- Description of stable portion -->
<!ELEMENT Stable_Portion (Wave_Unit_Type3+)>
<!-- It must have Element 1 -->
<!-- Element 0 is optional, you can hear it as vowel "A"
without Element 0. -->
<!-- Element 3 is optional. It gives effect to be surely
"A." -->
<!ELEMENT Wave_Unit_Type1 ( Element_0?,
Element_1_for_A)>
<!ELEMENT Wave_Unit_Type2 ( Element_0?,
Element_1_for_A, Element_2_for_A)>
<!ELEMENT Wave_Unit_Type3 ( Element_0?,
Element_1_for_A, Element_2_for_A, Element_3_for_A?)>
<!-- Element 0, Element 1, Element 2, and Element 3 are
-->
<!ELEMENT Element_0 (WaveData)>
<!ELEMENT Element_1_for_A (WaveData)>
<!ELEMENT Element_2_for_A (WaveData)>
<!ELEMENT Element_3_for_A (WaveData)>
]>
<Independent_Vowel_A>
</Independent_Vowel_A>
And also, these are descriptions of speech elements of
stable portion, for a syllable, japanese
utterance vowel "I" , for a syllable, japanese
utterance vowel "U" , japanese utterance vowel "E", and for a
syllable, japanese
utterance vowel "O."
<!DOCTYPE
Independent_Vowel_I [
<!ELEMENT Stable_Portion (Wave_Unit_Type2+)>
<!ELEMENT Wave_Unit_Type2 ( Element_1_for_U,
Element_2_for_I)>
]>
Element 2 of "I" differs from one of other vowels like "O" and
"E."
It is rather rubbing noise than sound in box of mouth.
<!DOCTYPE Independent_Vowel_U [
<!ELEMENT Stable_Portion (Wave_Unit_Type1+)>
<!ELEMENT Wave_Unit_Type1 ( Element_0?,
Element_1_for_U, Element_2_for_U?)>
]>
Element 2 and more of vowel
"U" gives effect to be surely
"U."
<!DOCTYPE Independent_Vowel_E [
<!ELEMENT Stable_Portion (Wave_Unit_Type1+)>
<!ELEMENT Wave_Unit_Type1 ( Element_0?,
Element_1_for_U, Element_2_for_E, Element_3_for_E)>
]>
Element_2_for_E is like weakened element_2_for_O.
Element_3_for_E is emphasized relatively due to weakened
element_2_for_E.
And also, following is another representaion of "E."
<!DOCTYPE Independent_Vowel_E [
<!ELEMENT Stable_Portion (Wave_Unit_Type1+)>
<!ELEMENT Wave_Unit_Type1 ( Element_0?,
Element_for_O, Element_2_for_E,Element_3_for_E?)>
]>
In this representation, element 3 and more of vowel
"E" gives effect to be surely
"E." And element 0 is similar to element of "U."
<!DOCTYPE Independent_Vowel_O [
<!ELEMENT Stable_Portion (Wave_Unit_Type1+)>
<!ELEMENT Wave_Unit_Type1 ( Element_0?, Element_1_for_U,
Element_2_for_O, Element_3_for_O?)>
]>
Element_3_for_O is relatively too weak than element_2_for_O.
And here is an attention that measurement actual value of each element
isn't fixed one, isn't constant, they are changeable
according to circumstances. Each element is relatively defined between
each others, but this opinion is still a hypothesis.
And another important thing is that all elements are relation, of which
origin is common. They are not independent. For example, there are three portions
corresponded to glottis's change in wave.
Sum of elements makes a speech signal. However, if change solely
one element by its own way, sound may be broken and quality of the
speech signal maybe will be poor.
No.10,
27 October
2007
<
Pattern Recognition Based on Elements of Speech Signal >
In speech signal, the frequency and its band of main elements are not
fixed, they vary depending on speaker or situation. To begin search for
pattern matching or pattern recognition, initial values about them can
be estimated by frequency response by FFT analysis of a certain part of
speech signal. The procedure may be combination with mathematics
calculation and search technique developed by
AI study. Calculation values as some index and judgment by
certain condition term. Human speech signal is vary, so, search based
on certain method will be resolved is Not guaranteed. An idea is
multi-thread search, that simultaneously some methods are done until
one of them will be resolved. (about
matching
and learning) Another idea is statistical pattern recognition
method of which feature extraction is based on structure features like
elements, trace along time, and so on. Picking up effective
discriminative features are significant.
MENU of
SEARCH for Pattern Recognition
- Getting Period or Cycle like tone, pitch,
and beat by close signal waves.
They are basic information for analysis following.
- Getting Elements synchronized with Glottal Signal
Utilizing that signal is modulated by glottal signal. This also may be
utilized for sounds separation method.
- Trace toward Target Tuning Structure along time dimension. (6)
Paths toward target may differ some by speaker or situation, but target
structure is same. Recognizing speech structure of target tuned.
Efficiently and reasonably, change along time dimension might be done.
The change does not go out of one's way, but , it almost takes
near path on structure between current structure and target structure
under the condition of movement ability in mouth.
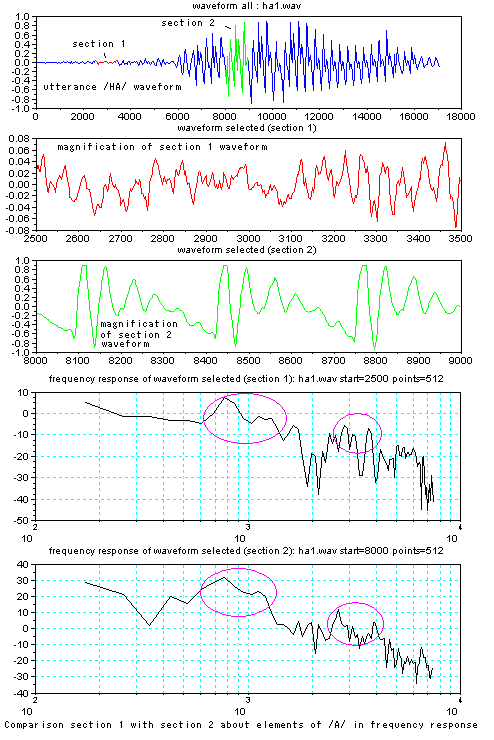
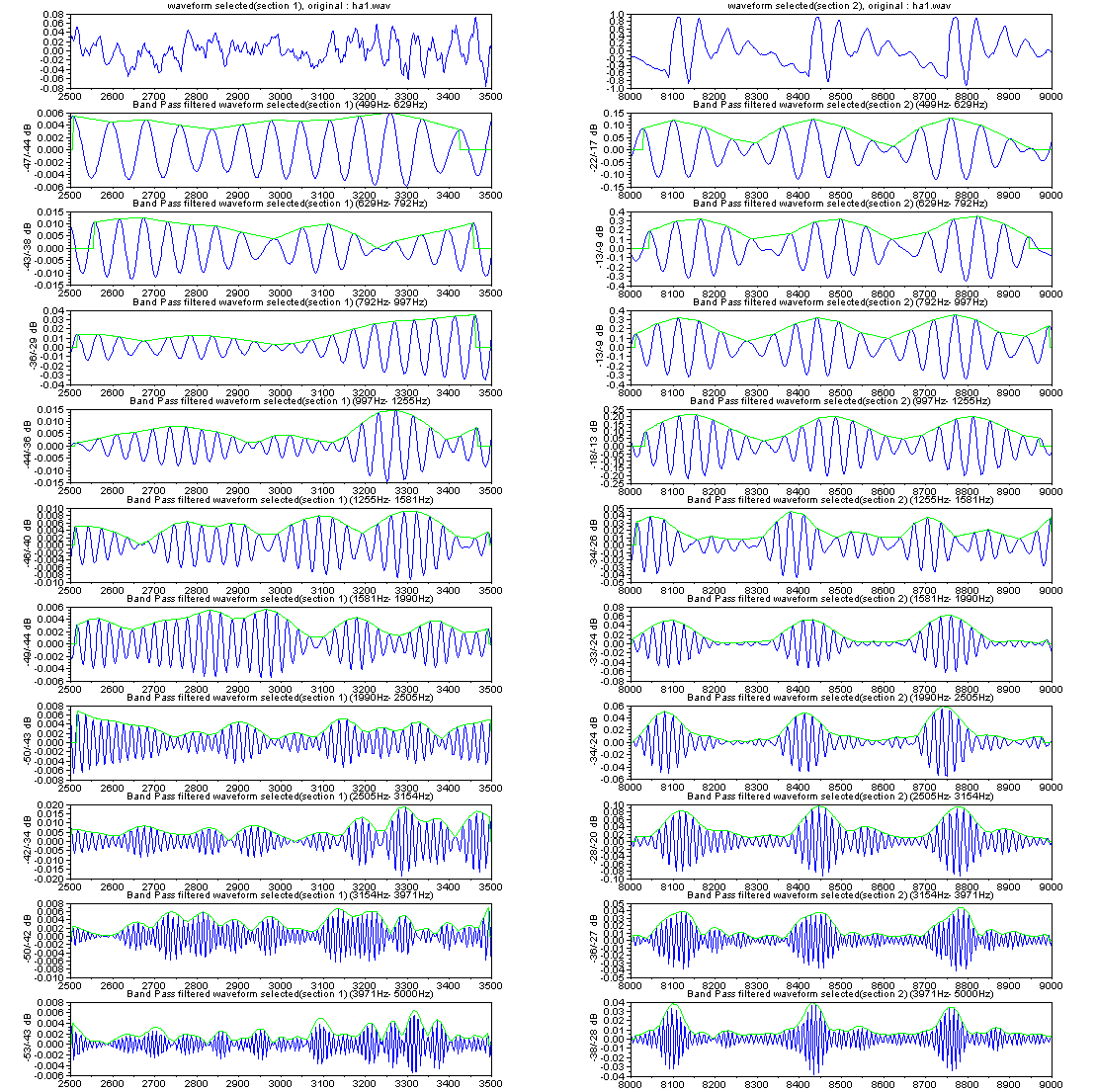
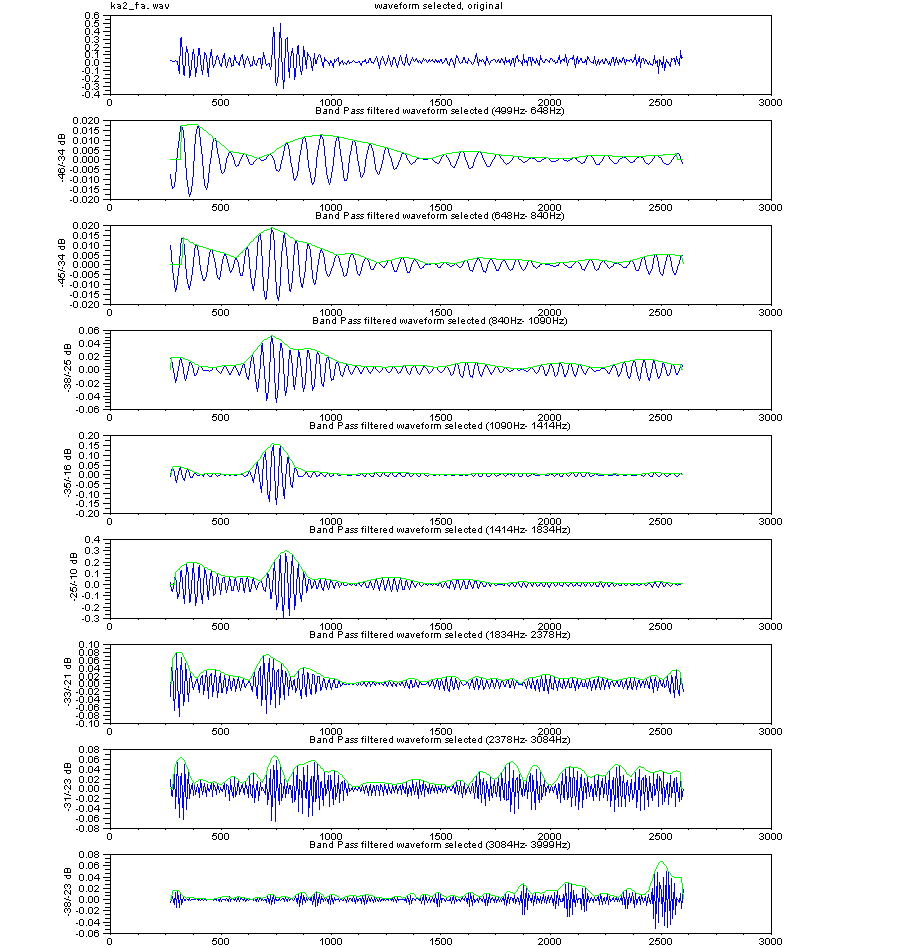
The right figures show a syllable
description by neighboring two sections in speech waveform of utterance
/HA/. In figure top, section 1 is a part of consonant, besides
section 2 is a part of vowel, in this case /a/. From the
view of frequency response, both sections have vowel /a/
features, which are marked by purple color
circle in figure middle. However, from the view of outputs of
filter bank (figure bottom), a sure difference
exists. In section 2, a part of vowel, output signals
synchronize with glottal signal, besides in section 1, output signals
are not in order well.
In like noisy signal of consonant portion, it includes feature of
following vowel /a/, and changes to the feature stable in vowel
portion. This is the /HA/ structure described by neighboring two
sections along time dimension. |
Outputs of filter bank (divided band quantity is 10)
You can look at more detail if you click the figure.
a filter bank program which
was used for this analysis
|
Structure of sound changes of times. This is a sample of change
of nasal sound, japanese utterance /NA/ and /MA/. /NA/ consists
of nasal sound plus /r/ plus /a/, besides /MA/ consists of nasal
sound plus /a/.
Sometimes, in conversation, structure of sound may be out of shape, as
similar to letter shape by hand writing against typewriter. We hear and
can understand easily as one word unit or as one sentence unit, but if
the speech is divide into syllable units and listen to each syllable,
sometimes their sounds are not clear, like be sound occurred by the
force of inertia, and are hard to discriminate only from the view of
sound structure. So, as present speech recognition technique, total
speech recognition should be done including to refer possible
candidates of one word unit or one sentence unit.
"Synthesis
ability and detection ability are complemental."
No.10,
25 May
2008
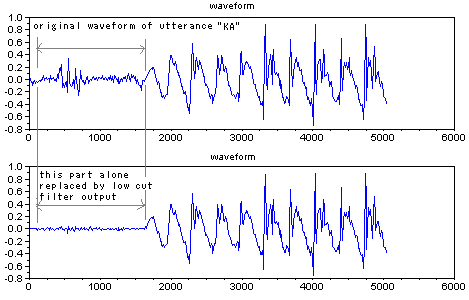
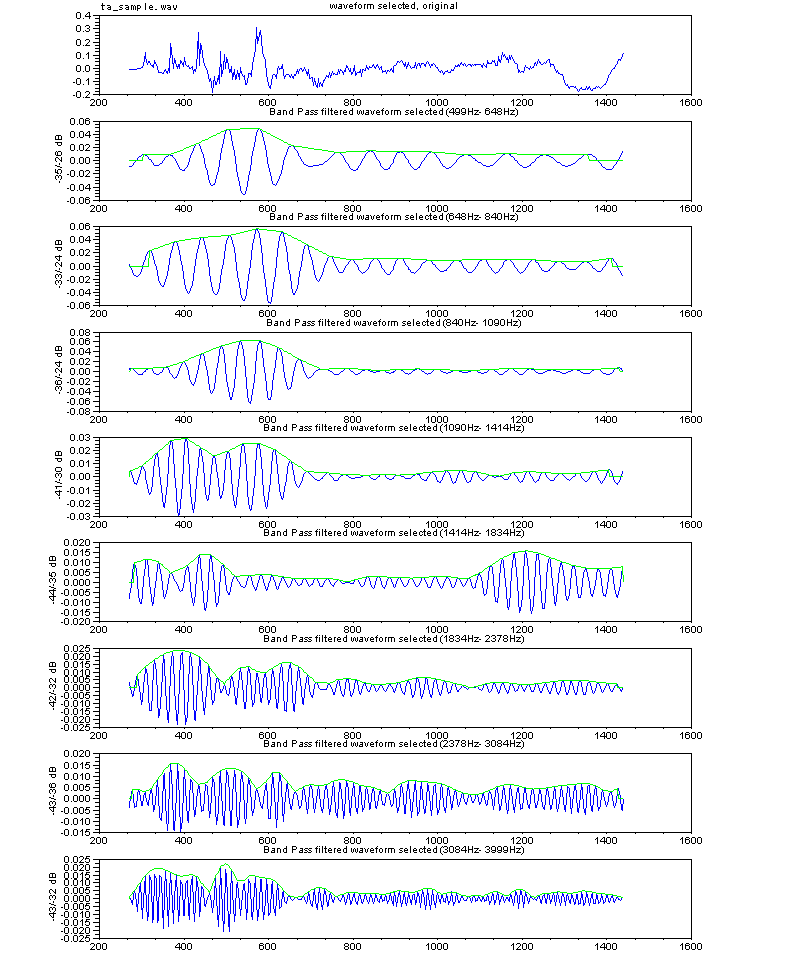
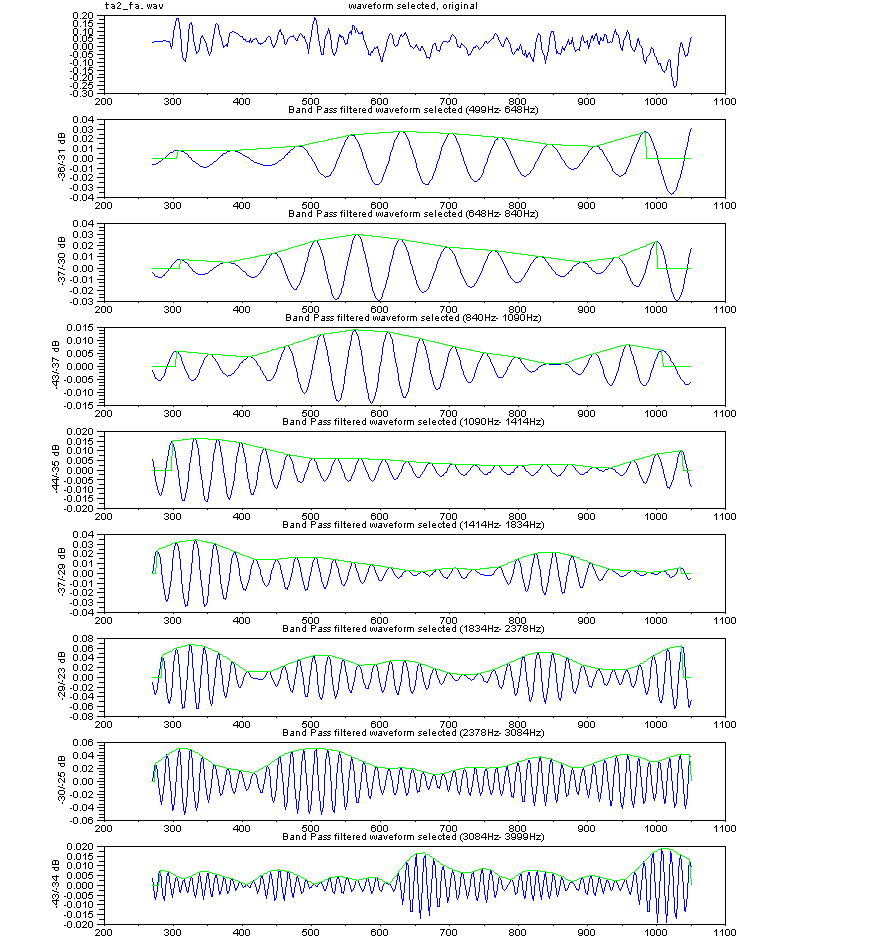
<Consonant structure example, transform utterance
"KA" to utterance "TA" >
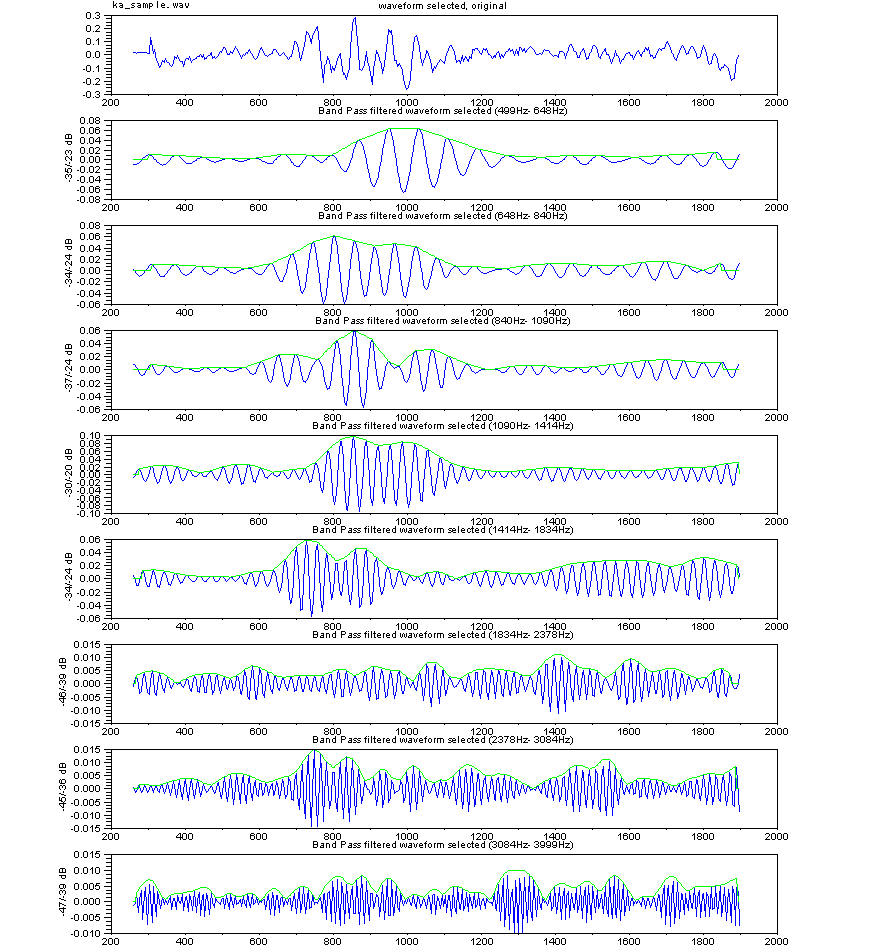
From the view of structure, beginning part of
utterance "KA" consists of two elements, which are cave sound in mouth
and strong breath turbulent flow sound. Meantime, beginning part of
utterance "TA" consists of, mostly, strong breath turbulent flow sound
along mouth close to open.
In figure right, upper waveform shows utterance "KA",
original waveform. And below one is waveform which is pulled element
out by low cut filtering on beginning part of utterance "KA." Below waveform sounds like utterance
"TA."
Turbulent flow sound or cave sound are sensitive to man to hear.
These sound waveforms differ much by speakers. So, to detect
these sound, not only frequency analysis method, but effective
alternate method had been better to be introduced.
Unvoiced sound, like /k/, /t/, and /s/ has no successful synchronize
signal, although voiced sound includes glottis signal as synchronize
signal.
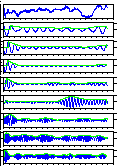
Let's study burst waveform
in turbulent flow sound or
cave sound. To compare them and find feature across them, for examples,
waveforms
of filter band which
consists of some band pass filters are shown in left figure.
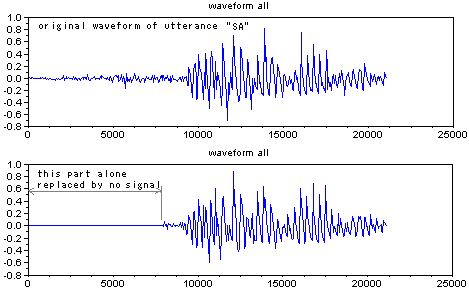
Another example is of utterance /SA/.
The bottom waveform of figures right shows waveform replaced initial unvoiced
portion of utterance /SA/ by no signal, and this waveform
sounds like utterance /TA/. For sound /s/, "some time
long stable sound caused by flow through closing mouth" is
one of key factor for /s/ identification.
And sonant depends on timing relate to glottis signal is
also known.
Another example. Consonant portion /h/ of /HA/ differs one of /HO/, because
/h/ varies depending on following vowel.
|
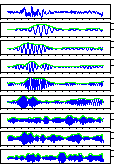
Waveforms in the below
figures are outputs of filter
bank (divided band quantity is 8).
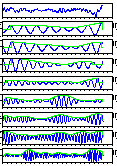
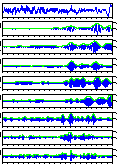
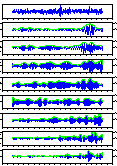
Comparison unvoiced sound /k/, /t/, and /s/ by a male speaker and a
female speaker. You can look at more detail if you click each figure.
|
by a male speaker
|
by a female speaker
|
/k/
|
|
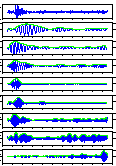
|
/t/
|
|
|
/s/
|
|
|
|
No.7,
15 April
2008
<A Sound in Mouth differs vowel "O" from vowel
"U" >
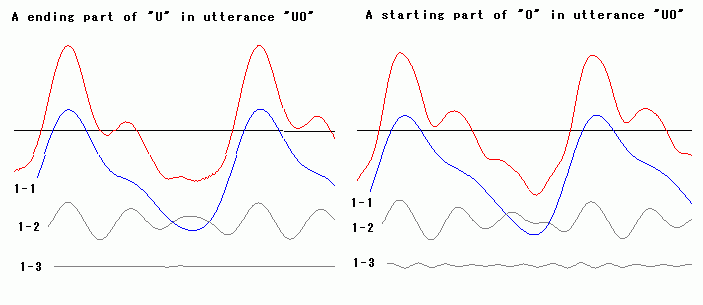
To study difference japanese vowel "O" from japanese
vowel "U," the figure below is a comparison a ending
part of "U" portion in utterance japanese vowels "UO" with a
starting part of "O" portion in utterance japanese vowels "UO."
The difference is that element 1-3 appears clearly, that maybe
means as a new sound addition in utterance process in mouth.
|
|
|
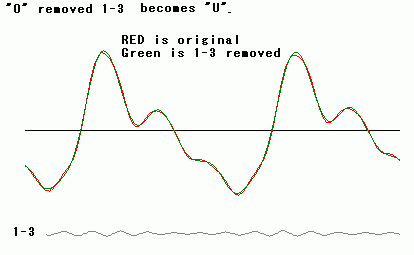
And the figure upper is a comparison original (color
red) with element 1-3 removed one (color green), which are same
starting parts of "O" portion in utterance japanese vowels "UO."
If element 1-3 is removed from original,
it can
be heard as "U"
instead of "O." Both forms are similar as look, but they
are heard as different vowel.
As sample, there is a portion of utterance japanese vowels "UO."
|
And, there is a turing portion from "O" to "E" of
utterance japanese vowels "OE." Beside
element 2 weaken, element 3 (that is element 2 for "E")
strengthen during turing portion from "O" to "E." This is the voice which
consists of both element 2 and element 3 of "OE."
And, there is a turing portion from "U" to "A" of utterance
japanese vowels "UA" that is "UWA." During
turing portion from "U" to "A", vibration
frequency of element 1 becomes higher. Beside element 2 strengthen,
vibration
frequency of element 2 does not change so much than one of element 1.
This may mean that both "U" and "A", element 2 sounds
nearly same space in mouth, but level of element 2 of "U"
weaken due to tube formed mouth that functions high cut filter.
And element itself has its inner structure. There is most
difference
between "A" and "U" in element 1. And, the difference
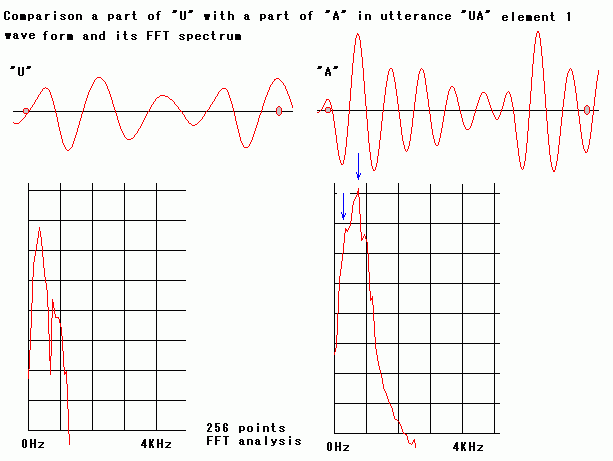
is microscopically. The figure below is comparison a part of of
"U"
with a part of "A in utterance "UA"
element 1 wave form and its FFT
spectrum. Hearing element 1 of "UA"
solo can be heard as "UA" roughly.
Although both wave form of U" and wave form "A" are similar to
vibrating wave if its vibration cycle adjust to be nearly equal, there
is microscopically difference in element 1 of "UA." Current analysis
method is not enough to recognize these microscopically feature.
However, analyzing elements
of the element makes difference clear. There are main differences
in element 2 of element 1 of "UA" and element 3 of element 1 of "UA."
Result of FFT spectrum depends on kind of pre-process window and on
which section calculated of the wave form. In this example above,
right, spectrum of "A" has a
small peak (blue color arrow) at lower frequency side of top peak (blue
color arrow), comparing left, spectrum of "U." Both spectrums
shape are like a mountain due to narrow band filter to calculate
element 1 from original wave form.
No.9,
23 September
2007
A former home page:
A Study of Speech Recognition
based on Inner Structure
An opinion:
Speech Technology
and its contribution for Mankind Social
Epilogue:
epilogue
With gratitude:
 |
 |
|

|
old Open Directory Project mirror |
search scientific
information only |
a new search of
academic literature |
check HTML grammar
by W3C
|
No.114, 7 November
2018
This page first established on 17 July
2005.
Conclusion is "
At last, Mystery must be referred to Veda
immortal."


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}