
- 内部構造 によるパターン認識の研究 -
作者 Shun
English Japanese
|
|
- 内部構造 によるパターン認識の研究 - 作者 Shun English Japanese |
|
| もっとも
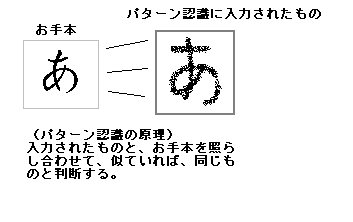
簡単なパターン認識の方法は、お手本と見比べて同じものなら、それと判断するものである。例えば、日本語の片かなの「あ」を認識することを
考えてみよう。右の図を見て欲しい。パターン認識する機械に、入力されたもの(右の手書きの「あ」)を、お手本(左の楷書の「あ」)とところどころ見比べ
てみて、だいたい同じものならば、入力されたものを「あ」と判断する。このパターン認識の方法は、入力されるものが、お手本とそれほど違わないときには上
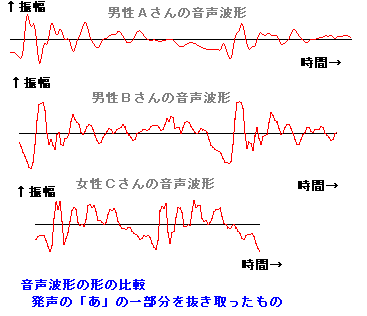
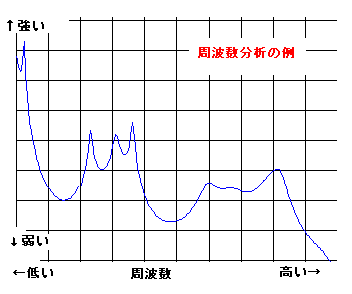
手く働くのだが、現実の世の中はそうう甘くはない。 さて、人が発声する声をマイクを使ってAD変換してコンピューターに取りんだ波形(縦軸が入力電圧の振幅、横が時間mS) の例を見てみよう。右図は3人分の「あ」の発声の波形の一部分を示す。3つの波形を比べれ見ると分かるとうり、同じ「あ」の発声であっても、波形の形は似 ているようであり、また、違いありそうなことが分かる。つまり、実際の音声の波形は 人や話し方で違いがあるのである。 もし、お手本を1個だけもっていたとしても、音声は人や話し方によって違いがあるので、認識が上手くいきそうにないことが推測できる。音声認識のソフトで 事前に学習するのは、その人や環境(マイクやアンプの周波数特性や話し方(緊張しているとか))に合うようにお手本をチューニングする作業をしているの だ。 通常、音声の波形そのものをパターン認識に使うことは少なく、より適した尺度に変換したものを使うことが多い。例えば、音声波形を周波数分析す ると、右図のように、幾つかの周波数で強さのピーク(ホルマント と呼ばれる)があらわれることが知られている。 ピークの逆の現象(抑圧される部分)も知られている。古くから、これらの特徴が音に「い」とか「あ」とかなどの意味付けしていると言わ れ ている。 さらに、時間の経過の順に周波数分析の結果を並べていくと、音声信号のなかのピークの周波数や強さなどは時間的になだらかに変動しているこ とがわかる。逆に、人工的に変 動しない音声をつくってみるとよく聞き取れない。 人がどのように音声から「あ」とか「い」とか「か」などを識別判断しているのかについては、長い間 数々の研究が行われているが、100%明確に説明でき る認識理論は まだ ないと言うのがホントのところであろう。 音声研究のリンク集 |
   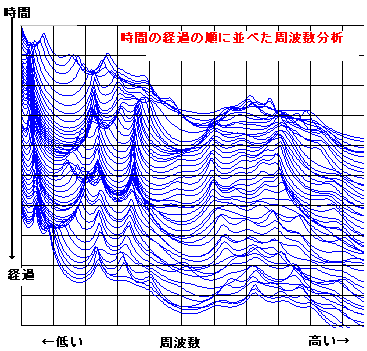 (注)上図の2つは、スペクトルの変化度合いを見やすくするため、 音声のLPC分析による周波数分析の結果を描いている。 |
人は話す音声をどのようなプロセスで認識できているのだろうか?
認識のプロセスについての仮説を考えてみた。
まず、人が話す時の、声の音の高さ(ピッチ)に依存しないようにすることと、
音色は歪成分によってあらわされることから、ピッチ同期の高調波成分の
分析を行い、それを測定された特徴データと使用する。
音声は、音源の音を口や鼻で歪ませて(または効果して)変形したものである。
一般的に、音源の音は単純なSIN波ではない。しかるに、音源の音を適当な、
比較的単純な系列の高調波成分をもつ波形と仮定し、
それがいかに歪まされて(効果して)測定された特徴データになったかを、
逆算推定計算する。この歪ませ方が、音素の意味と考える。
以上が認識に使う測定量の話である。次に、識別できることを考える。
多様な形があるもの中から、何であるか(which)を識別
できるのは、「多様な対象を限定した見方に押し込めてしまうような物差し(指標)が存在する。」、
と言う仮説を導入する。
具体的な例として、日本語の発声「あいうえお」をピッチ同期の高調波成分で
分析する。そして、ある歪み(効果)モデルにあてはめ、モデルに含まれる
係数を同定することで、歪み(効果)を定めることができるとする。
この係数(この例では23個)の主成分分析を行い、分散の大きな主軸を有限数の
物指し(指標)と見なして、発声の軌跡を描く。識別できるような違いが、
「あ」の発声箇所あたりと、「お」の発声箇所あたり、にあらわれているかどうか
チェックしてみる。
更に将来、
中国語などの場合、声の音の高さの変化によっても言葉の意味が違うそうなので、
音の高さの変化も考慮するモデル(音源の変化)への改造も必要であろう。
以上の仮説が正しいかどうかは、分からない。
まあ、真の原因を探るため、色々な考え方の試みがあってよい思う。
これは、ひとつの試みである。
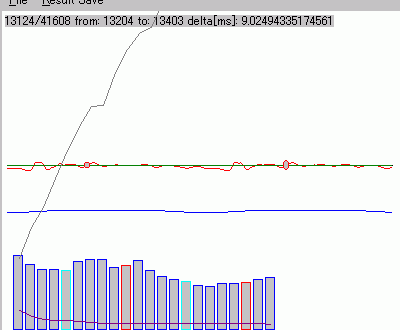
| 音声の分野でも、高調波成分を使った研究は既にいろいろある。 ここでは、認識のためには、音声の波形のピッチ情報を必ず取得利用しなくてはならないと考 えます。時間補正ができる理由で、直線位相FIR型のバンドパスフィルター の出力波形を使って、音声の基本波(ピッチ間隔)を求めている。直線位相FIR 型なので、一定の遅延時間となるため、時間補正することによって元の音声波形の位相遅れ差をゼロとすることができる。 実際には、人それぞれによって、基本波(ピッチ間隔)は高い低いと色々あるので、通過帯域が違う複数のバンドパスフィルターを使いその出力のから、上手く 検出に使えそうな妥当な出力信号を選ぶ過程が必要となる。 右図の例は、基本波の周期7.89mSの音声波形の一部分について、DFT(離散 フーリエ変換)して、基本波の高調波歪み成分を、dB(デシベル)単位で 求めたものである。少なくと人の聴覚のダイナミックレンジは60dB以上はあるだろう。ここでは、特 徴データとして、23倍の成分まで計算した。携帯電話のあのナローな もがもが音 をなんとか聞き取れることを考えると、まずは、 この辺で仮りにやってみてみようと考えた。この例のようなことを、音声の波形全区間に渡って計算していく。参考のため、付録1に、分析したデータの例を添 付しておく。 |
 |
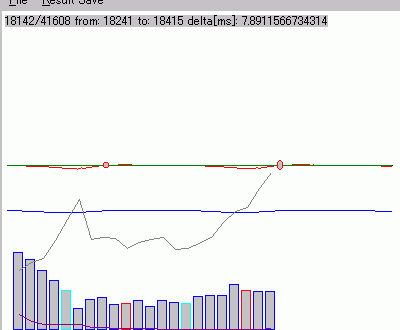
| 右図は、基本波の40次までの高調波成分を時間の経過順にプロットしたものであ
る。図中の横軸方向の左端は基本波成分である1倍を、右端が40倍の高調波成分を示す。また、時間の進みは、図中の上から下へと経過する。 高調波成分の時間経過の中から、周囲との相関が強い部分、周囲との相関が弱い部分、ノイズ(どうでもよい部分)を識別することは重要である。 例えば、上図の場合、低い次数の成分の相関は強いが、中高い域は、それほど重要ではないらしい。また、上図では、途中から、中域に相関の強い部分が発生 している。 下図では、低い成分に相関が強い部分があるとともに、中高域にも相関の弱い部分が存在することがわかる。 この様に、意図する特徴部分を浮き上がらせてノイズを削除していくことは、パターン認識の精度を上げることに期待できるであろ。 |
  |
| 音源を歪ませて音声にする。その歪ませ方が音素の意味であるとする(仮説)。 歪ませ方を記述する数学的な手法としては、てきとうな歪みモデルを設計し、歪みモデルの係数を逆算推定することを行う。 歪みは、非線形の出来事である が、こ れを、高調波成分の変換によって記述することを考える。 そして、その係数によって音素を識別することを試みる。 |
 |
| 具体的な歪みモデルの設計は、まだ、任意性が高く定まったものではない。今後、「これだ!」と言えるものを、カット アンド トライ で見つけださなくてはならないだろう。 |
| 「高い」があれば、その逆の「低い」も、どこかに存在する。「熱い」があればどこかで「寒い」もある。「高い」や「熱い」だけが、唯
一単独で存在している訳ではなく、そこには必ず相対的な相手が存在している。この相対的な相手同士がたがいに存在しあって、識別できる概念が成り立ってい
ることを、同時存在性と呼ぼ
う。
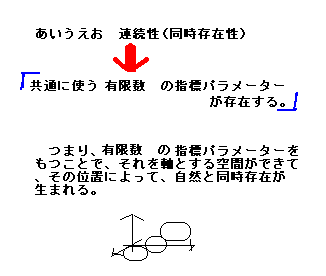
また、一般的に、概念の具現化したもの(Embodiments)は、 一般に、無限数の形をとりえるものである。 では、何故、ありとあらゆる形をしたものがあるのに、我々は識別できるのか? そこで、識別することができる必要条件を考える。仮説として、識別するこ
とができる必要条件を、「多様な対象を、限定した見方に押し込めてしまうような物差し(指標)が存在
する。」としてみよう。 例えば、日本語の母音の場合は、簡単に言うと、「あ」「い」「う」「え」「お」が同時存在している感じ。(しかも、明確に境界があるわ けではなく、その境は連続してつながっているようなイメージで。) 有限の数の指標がおりなす全体の空間があり、識別される個々の概念はその全体の空間の中で、それぞれに対応する部分空間たちで構成され ると考える。 つまり、有限数の指標を軸(パラメーター)を設定することで空間ができて、個々の概念たちは部分空間として位置を占めながら、互いに存
在し合っているのである(同時存在)。 |
 |
| 指標は、同じ種類の尺度の組み合わせではなく、違う種類の特徴を抽出する幾つかの尺度を 組み合わせて成る、と考えた方がよいだろう。 おそらく、指標(となるパラメーター)は、言語毎(方言毎)に違うことだろう。 我々日本人が、フランス人の異種の母音が(フランス人には違っても)同じに聞こえてしまうように、指標そのものも、言語毎に違うことだろう。 |
| 指標としてのパラメーターを探す一つの試みとして、多変量解析でよくもちいられ
る主成分分析を、歪みモデルの係数について行ってみた。
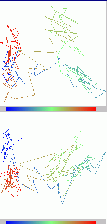
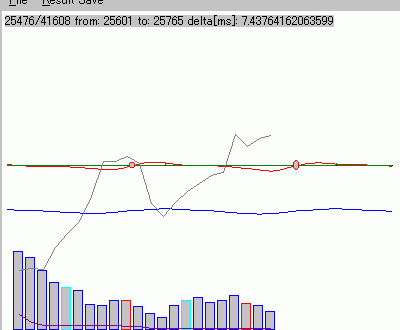
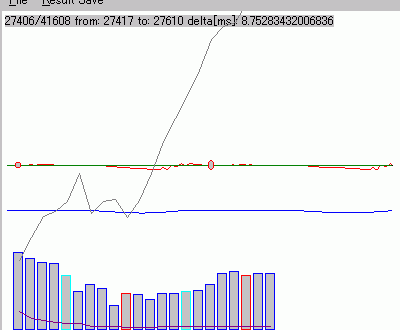
右図は、「あいうえお」発声の軌跡を描いたものでる。ためしに、主成分分析の結果の、第1と第2、第1と第3、それぞれの主軸への投影
の軌跡を描いてみた。 これを見ると、「あ」あたりの部分空間と「お」あたりの部分空間は、第3軸で、分離傾向にあることが分かる。
|
 |
| 個人ホームページ専門の 検索エンジンリンク集 |
Open Directory プロジェクトについて |
科学技術専門の 検索サイト |
W3CによるHTMLの Web文法チェッカー |
|
このWEBサ
イトを閲覧して頂き ありがとうございました。
|
転記やリ
ンクはご自由に。
since 2005.7.17 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}