
- 音声の内部構造 によるパターン認識の研究 -
作者 Shun
English Japanese

|
|
- 音声の内部構造 によるパターン認識の研究 - 作者 Shun English Japanese |
|
| もっとも
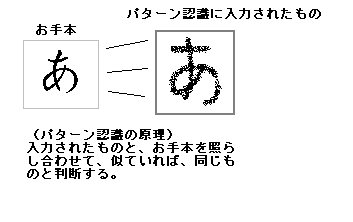
簡単なパターン認識の方法は、お手本と見比べて同じものなら、それと判断するものである。例えば、日本語の片かなの「あ」を認識することを
考えてみよう。右の図を見て欲しい。パターン認識する機械に、入力されたもの(右の手書きの「あ」)を、お手本(左の楷書の「あ」)とところどころ見比べ
てみて、だいたい同じものならば、入力されたものを「あ」と判断する。このパターン認識の方法は、入力されるものが、お手本とそれほど違わないときには上
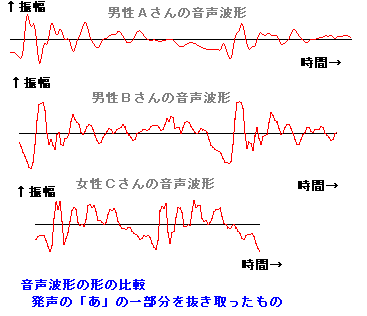
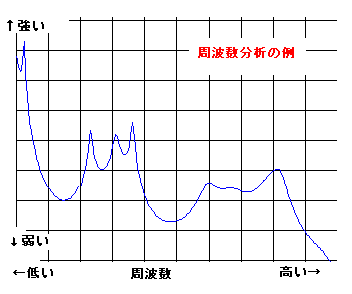
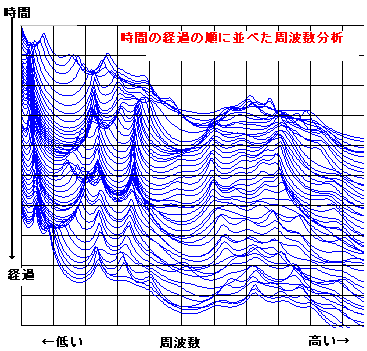
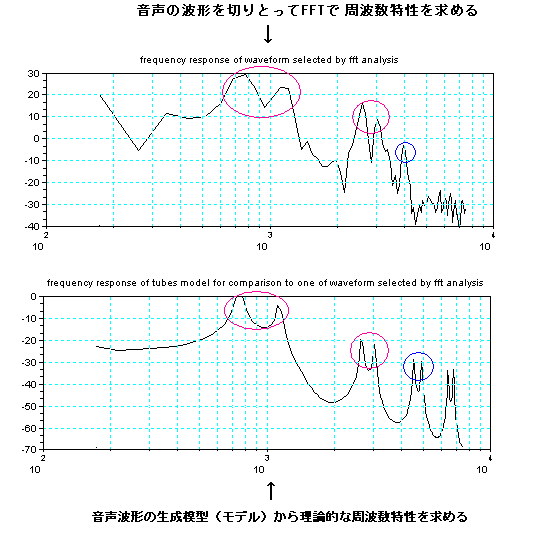
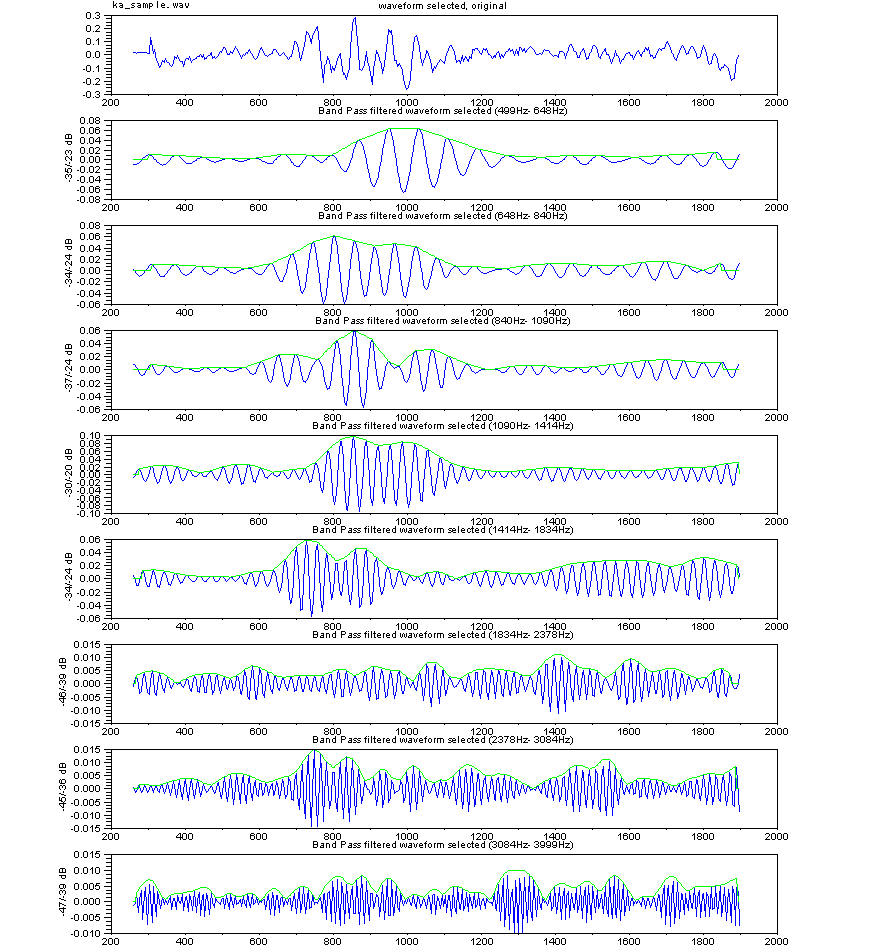
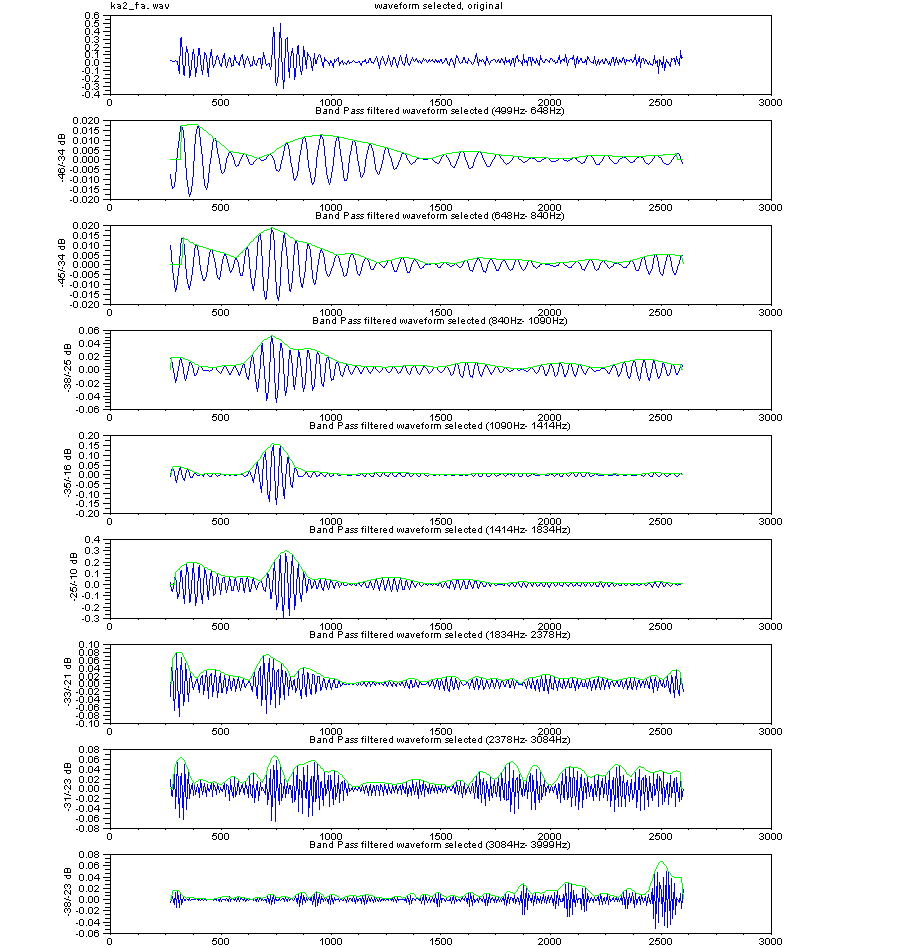
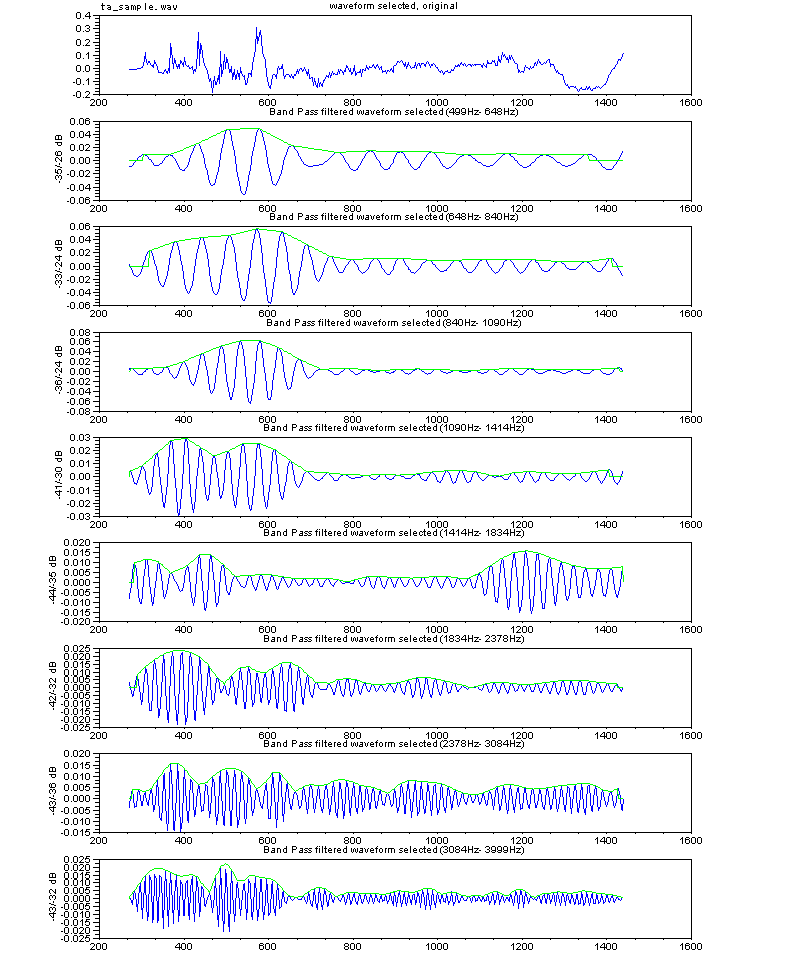
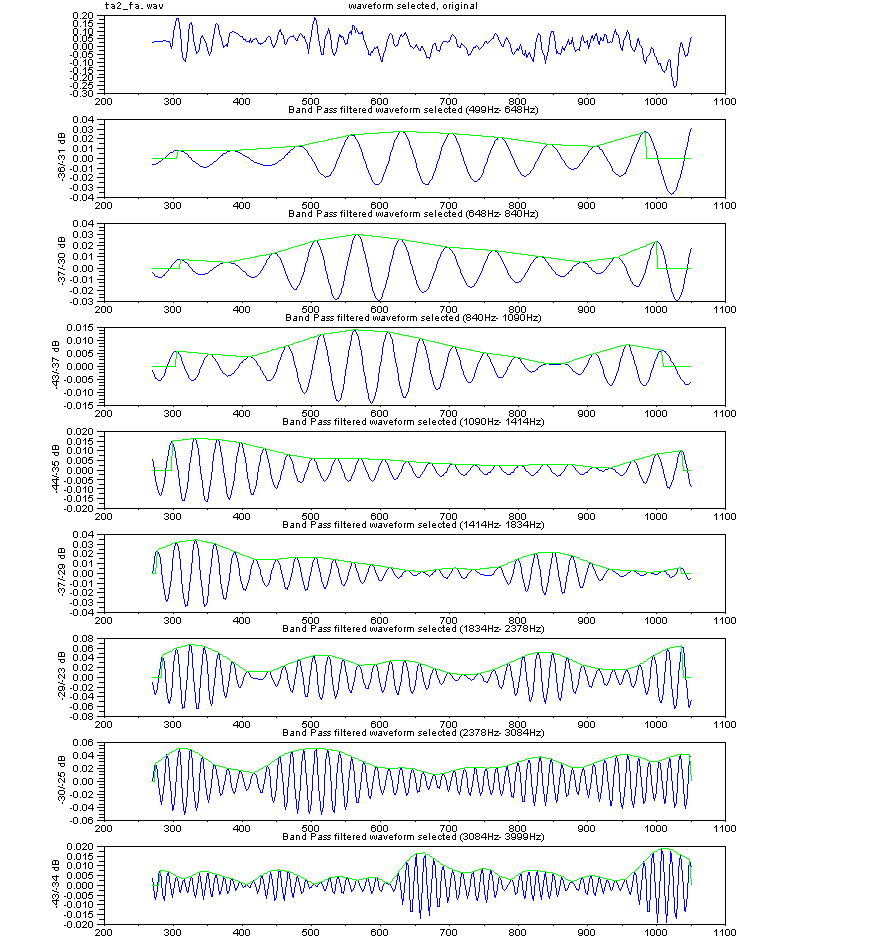
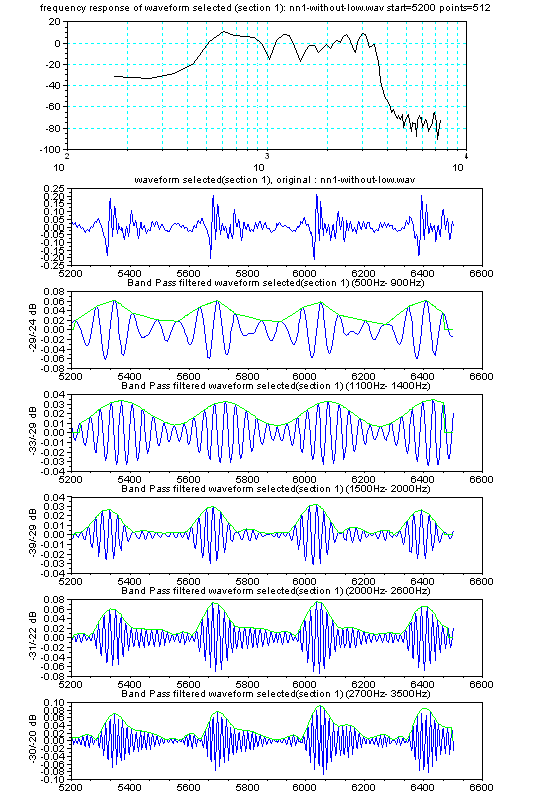
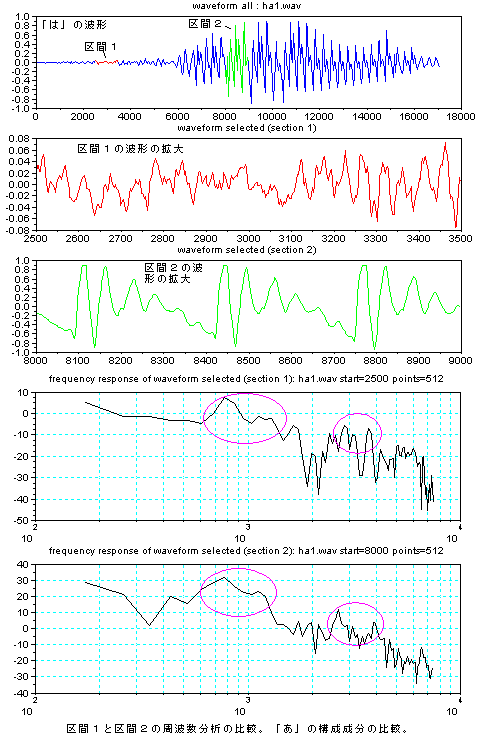
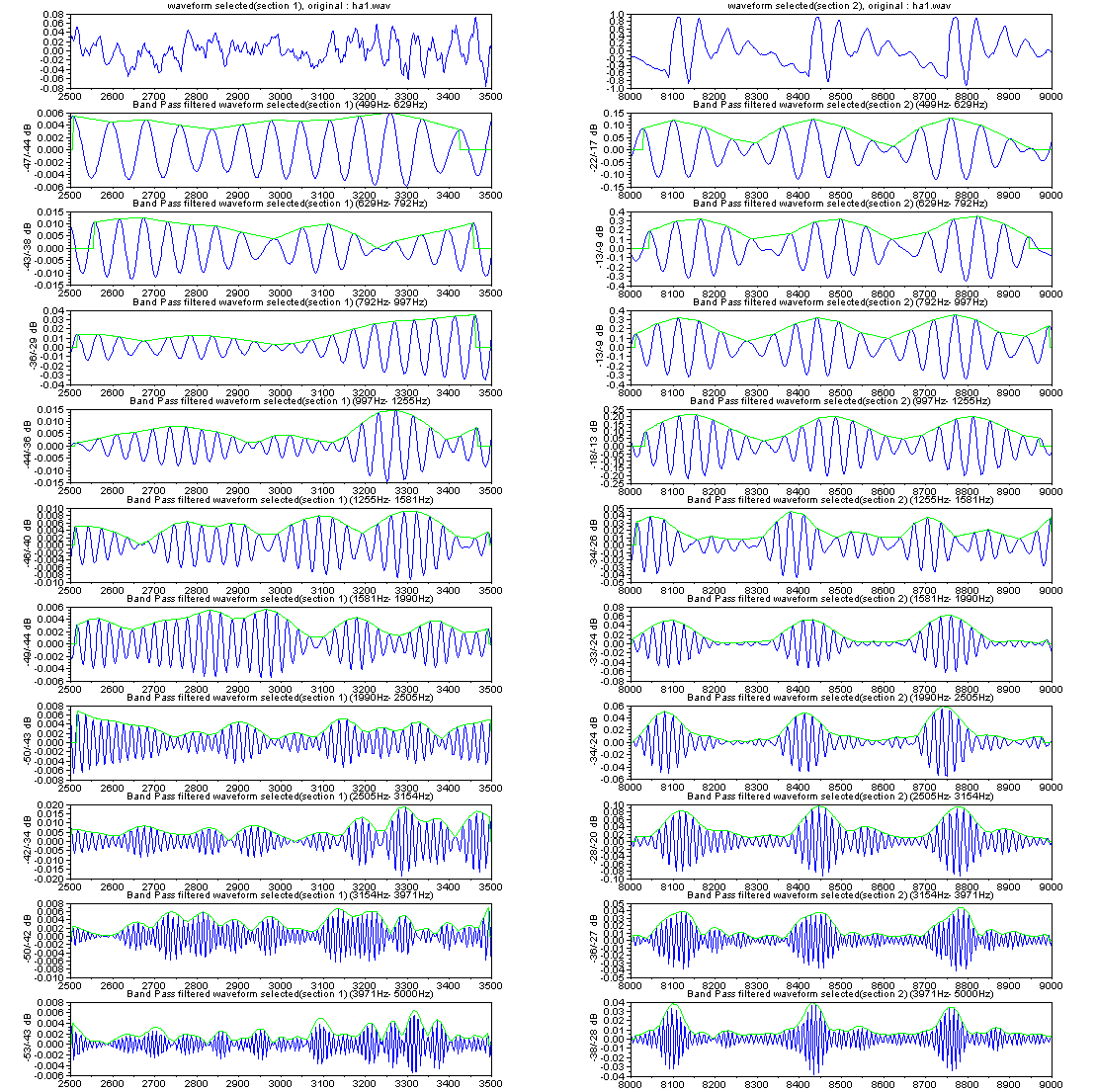
手く働くのだが、現実の世の中はそう甘くはない。 さて、人が発声する声をマイクを使ってAD変換してコンピューターに取りんだ波形(縦軸が入力電圧の振幅、横が時間mS) の例を見てみよう。右図は3人分の「あ」の発声の波形の一部分を示す。3つの波形を比べれ見ると分かるとうり、同じ「あ」の発声であっても、波形の形は似 ているようであり、また、違いありそうなことが分かる。つまり、実際の音声の波形は 人や話し方で違いがあるのである。 もし、お手本を1個だけもっていたとしても、音声は人や話し方によって違いがあるので、認識が上手くいきそうにないことが推測できる。音声認識のソフトで 事前に学習するのは、その人や環境(マイクやアンプの周波数特性や話し方 例えば緊張しているとか)に合うようにお手本をチューニングする作業をしている の だ。 通常、音声の波形そのものをパターン認識に使うことは少なく、より適した尺度に変換したものを使うことが多い。例えば、音声波形を周波数分析す ると、右図のように、幾つかの周波数で強さのピーク(ホルマント と呼ばれる)があらわれることが知られている。 ピークの逆の現象(抑圧される部分)も知られている。古くから、これらの特徴が音に「い」とか「あ」とかなどの意味付けしていると言わ れ ている。 さらに、時間の経過の順に周波数分析の結果を並べていくと、音声信号のなかのピークの周波数や強さなどは時間的になだらかに変動しているこ とがわかる。逆に、人工的に変 動しない音声をつくってみるとよく聞き取れない。 人がどのように音声から「あ」とか「い」とか「か」などを識別判断しているのかについては、長い間 数々の研究が行われているが、100%明確に説明でき る認識理論は まだ ないと言うのがホントのところであろう。 音声の波形の生成を理解してみよう 日本語5母音の特徴 音の構造の記述, 変化モデル(子音) 音声の内部構造によるパターン認識とは 音声信号の分布と 構造の極点の関係について 音声技術の人間社会(Mankind Social)への貢献 音声研究のリンク集 |
    (注)上図の2つは、スペクトルの変化度合いを見やすくするため、 音声のLPC分析による周波数分析の結果を描いている。 |
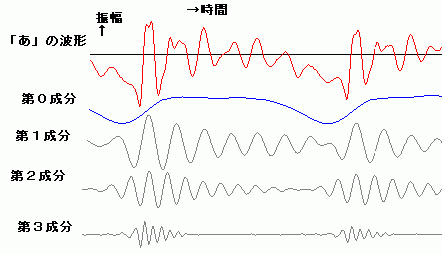
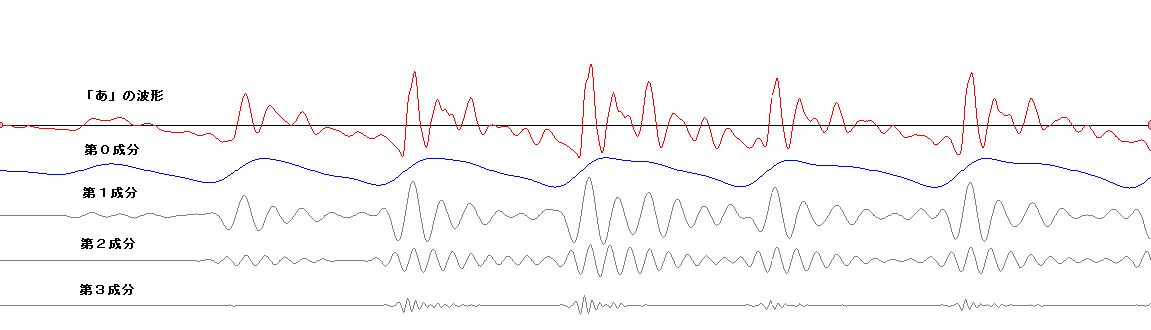
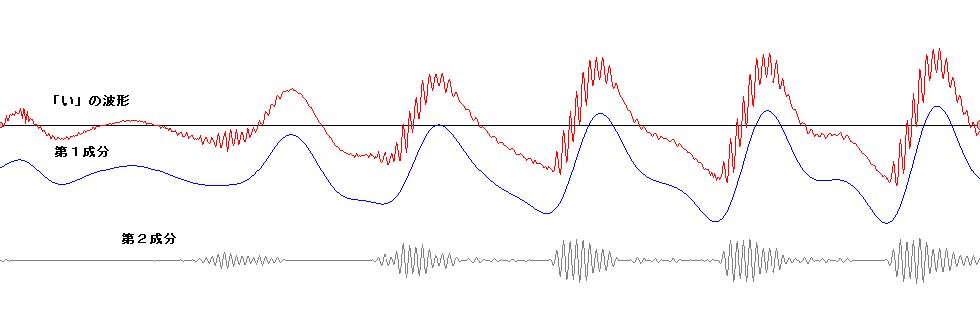
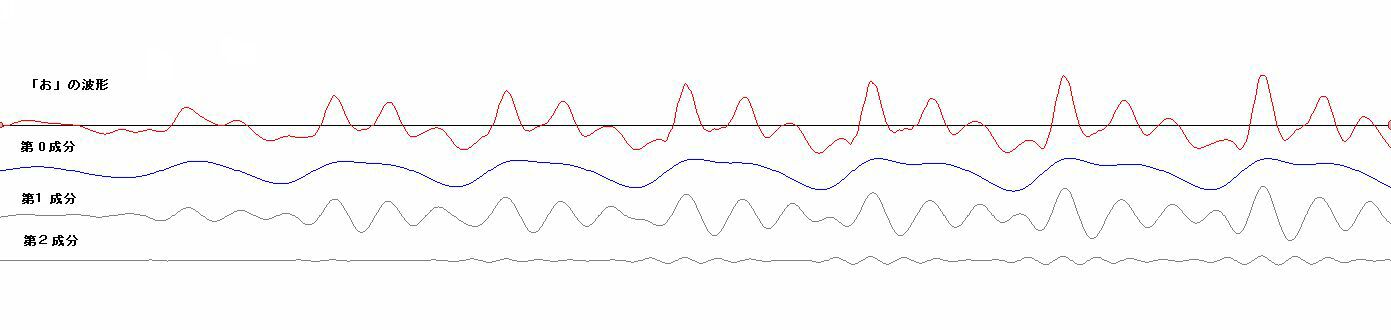
| 音声の波形は幾つかの構成成分に分解できるようだ。右の図は、人が「あ」と発
声したものをコンピューターに取りこんで、てきとうな周波数帯域ごとの成分を計算し
て、構成成分を求めたものである。赤色のぎざぎざした波形が、もと
の「あ」の波形である。その下の、第0成分から第3成分までの4つの波形が示してあるが、この4つの波形を全部足し合わせて合成すると、おおよそ、赤色の
もとの「あ」の波形の形になる。青色の波形は主に発声時の喉の振動から起因する成分で、音程の高さを決める。下の灰色の波形は、喉の振動がトリガーとなっ
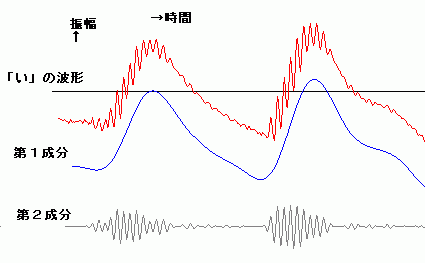
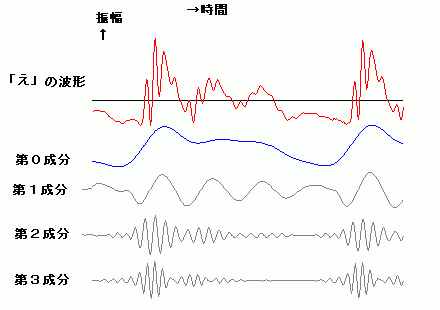
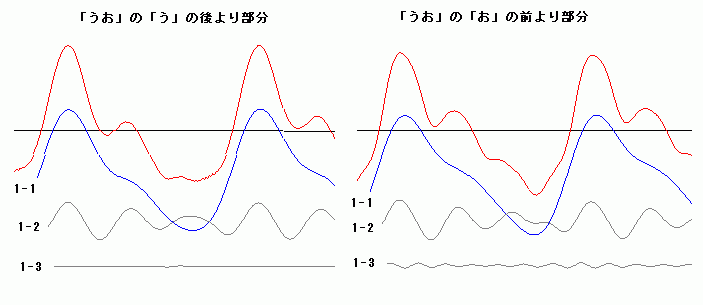
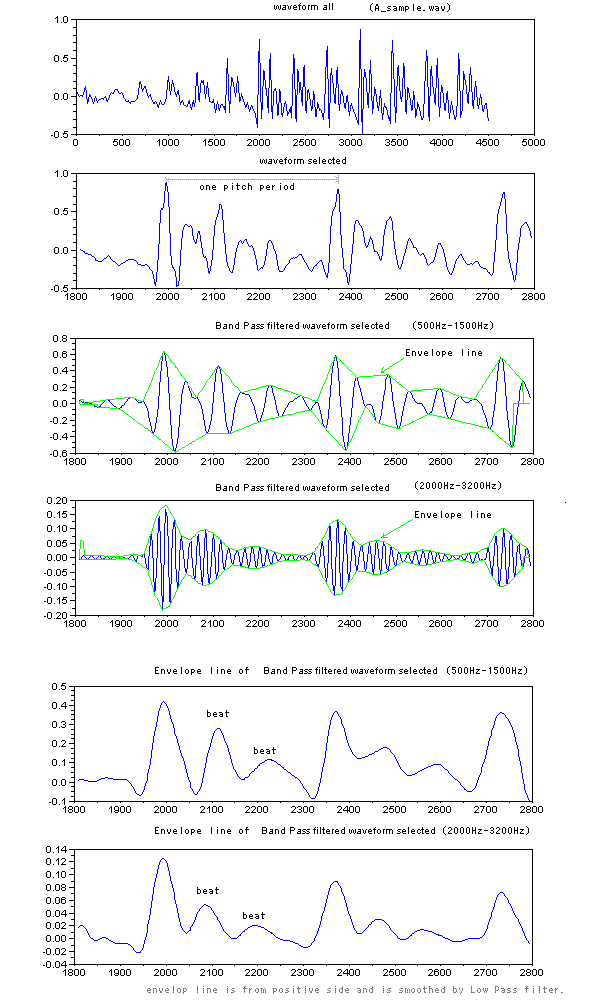
て発生するより高い振動数をもつ信号たちで、喉の信号が起点する周期で、バースト状に発生する。さらによく観察すると、それは、単純な正弦波ではない。 「あ」は、より高い振動数をもつ何段かの階層的な成分により構成されていたが、次に、「い」を見てみよう。「い」の場合は、主に、土台となる成分(右図で は青色の第1成分)と、それにまとわりつく雑音の様なごちゃごちゃした信号(右図では灰色の第2成分)から、構成される。仮に、「い」から第2成分を差し 引くと、「う」に聞こえる。 次に、「え」の場合を見てみよう。「え」は、主に、それだけ聞くと「お」に聞こえる第1成分と、「え」を特徴付ける第2成分から構成されるようだ。第3成 分を付加すること で より「え」ぽっく聞こえるようになる。 以上に示したものは安定した波形の一部分を抜き出したものである。実際の発声時には、動的な生成が行われて安定した波形になっていく。波形の安定した部 分 よりむしろ、動的に生成が行われる部分の方で、人は音節の判別していると思われる。このことが、連続発声したものから一部分を抜き取って聞くと(連続音で 聞こえた音節と違った)別の音節の音に聞こえる現象を説明する手がかりになると予想している。 動的な変動を観察するために、ちょっと分かりにくいが、単音節の発声の初期の過渡的な部分の波形の例(「あ」、「い」、「う」、「え」、「お」)をリンクしておこ う。 |
   |
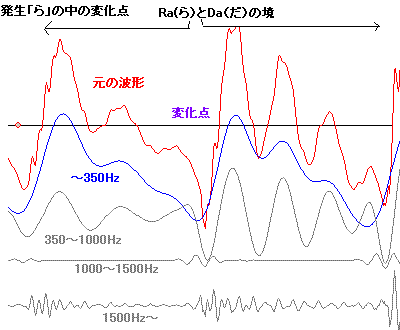
さて、「あ」は元気がいい波形たちを誘起させるが、逆に音を抑圧する物もある。下図は、ま行の「む(mu)」の前半の子音部分と後半の母音部分を比較し たもの である。子音部分と母音部分は、同じ周期性をもった成分(灰色)をもっている。しかし、子音部分では母音部分に比べて振幅の大きさが極端に小さく、抑え込 まれていることが分かる。母音部分になって、抑えこみから解放されて、青色の波形ともども元気がある波形なる。 参考に、単音節の「ま(ma)」を発声したときのmからaへの変化の波形をリンクし ておこう。 |
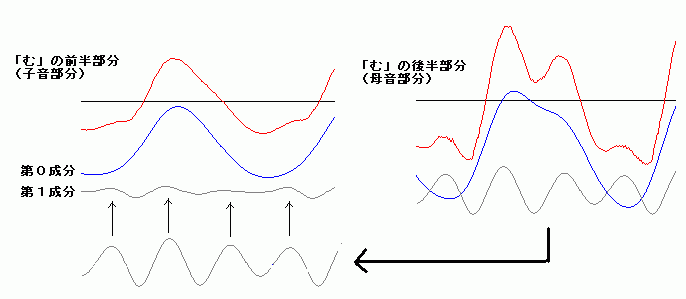 |
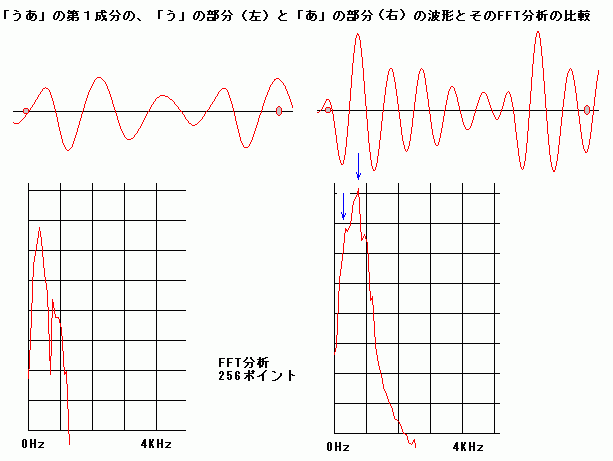
一般的に、 子音部分はまったく同じと言う訳ではなく、後続する母音に引きずられて(後続する母音の特徴を内にもつように)変形する傾向があるようだ。 |
| 推定するもの estimated factors |
種類 kind |
この特徴が存在する理由。または、決定つけるもの。 Reason why the feature exists. Or, principle to decide it |
|
| 共鳴パラメーター resonance parameters |
r1,l1 | /a/ | 口からの放射効率最大の原理 principle of maximum radiation from mouth by using two waves |
| /e/ | 1つと2つの波のよる停留値 stationary point by using one wave and two waves |
||
| /u/,/i/ | その他 other |
||
| r1,l1,r2,l2 | /o/ | 拡張方法 2管模型から3管模型へ。 第1管と2管は口からの放射効率最大の原理 、第2管と3管は「う」のようにつなぐ。 Extend method, from 2 tubes model to 3 tubes model. 1st and 2nd tube follows principle of maximum radiation, 2nd and 3rd follows like /u/. |
|
| rl | 口内での共鳴の効果の強さ rate of resonance effect in mouth |
|
|
| ノイズ noise |
性質 nature |
定常,バースト constant,burst |
流体の境界条件 turbulent boundary |
| 周波数分布 frequency range |
/i/,/s/,/t/と /r/の開始時(start mark of /r/) |
人の器官の物理的なつくりによる制約? Are they determine by physical of human vocal organs ? |
|
| 重畳 superpose |
単独、元を更に歪ませて発生(濁音) sonant( more disturb origin),independent |
ノイズを付加する方法の種別 classification of noise superpose method |
|
| 効果時間 effective duration |
生存時間 survival rate |
/t/,/p/ | 最小判定単位は1ピッチ程度? Is the unit to judge a pitch duration ? |
| 突発性 break |
/p/ | 同上 same as above ? |
|
| 消音された suppressed |
消音された箇所 portion to be suppressed |
/m/,/n/,/N(nn)/ | 後続の母音との比較 ? 鼻を使って音素数を増やしたい。 Compare with following vowel ? To increase kind by using nose effect |
| 音程 tune |
ピッチの変化 controlled pitch |
平坦,上がり,下がり stable, rise, fall |
状態変化はこの3つの組み合わせからなる。 音程を使って音素数を増や
したい。 any state will be composed from these 3 states. To increase kind by using tune. |
| 「う」と「お」の違いを探るため、「うお」と発声したときの波形成分を比較してみた。 下図は、「う」の後半と「お」の前半の部分を比較したものである。両者の違いは、1−3成分がはっきりと現れてきていることである。これは、発声している 口の中での響き音(1−3)が追加されたことを意味すると考えられる。 |
 |
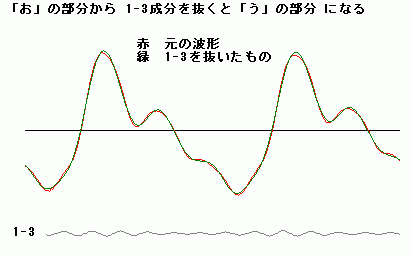 |
| ちなみに、「お」の前半の部分から1−3成分を抜きとった波形をつないで聞くと、「うお」は「う」のままのように聞こえる。上図は、
赤色が「お」の前半部分と、緑色が
それから1−3成分を抜き取った波形を比較したものである。波形の形としてはほとんど同じように見えるが、聞くと違いがでるのである。 参考に、「う」から「お」にうつり変わるときの波形をリンクしておこう。 |
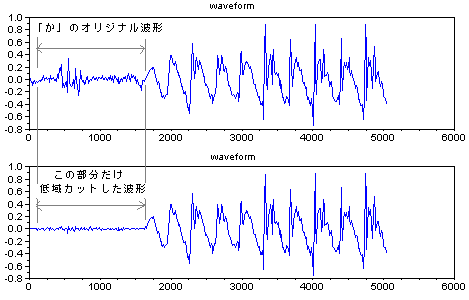
| 構造的に見ると、「か」の音のはじめの部分は、発声するときに少し口が開いて口に空洞ができてそこで発
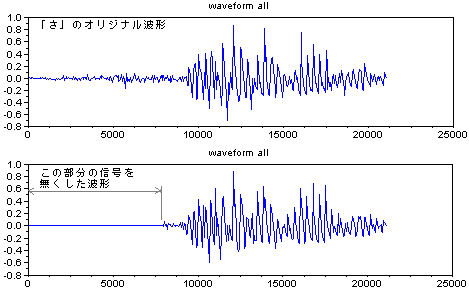
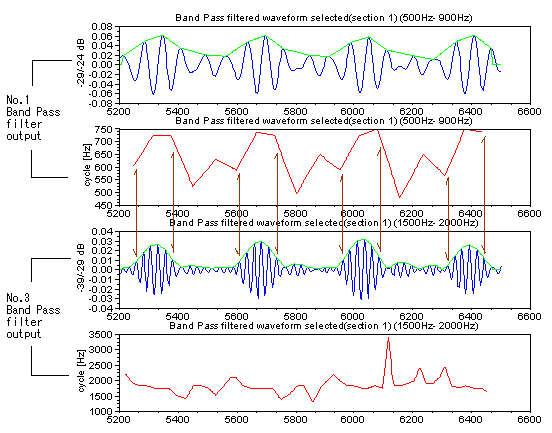
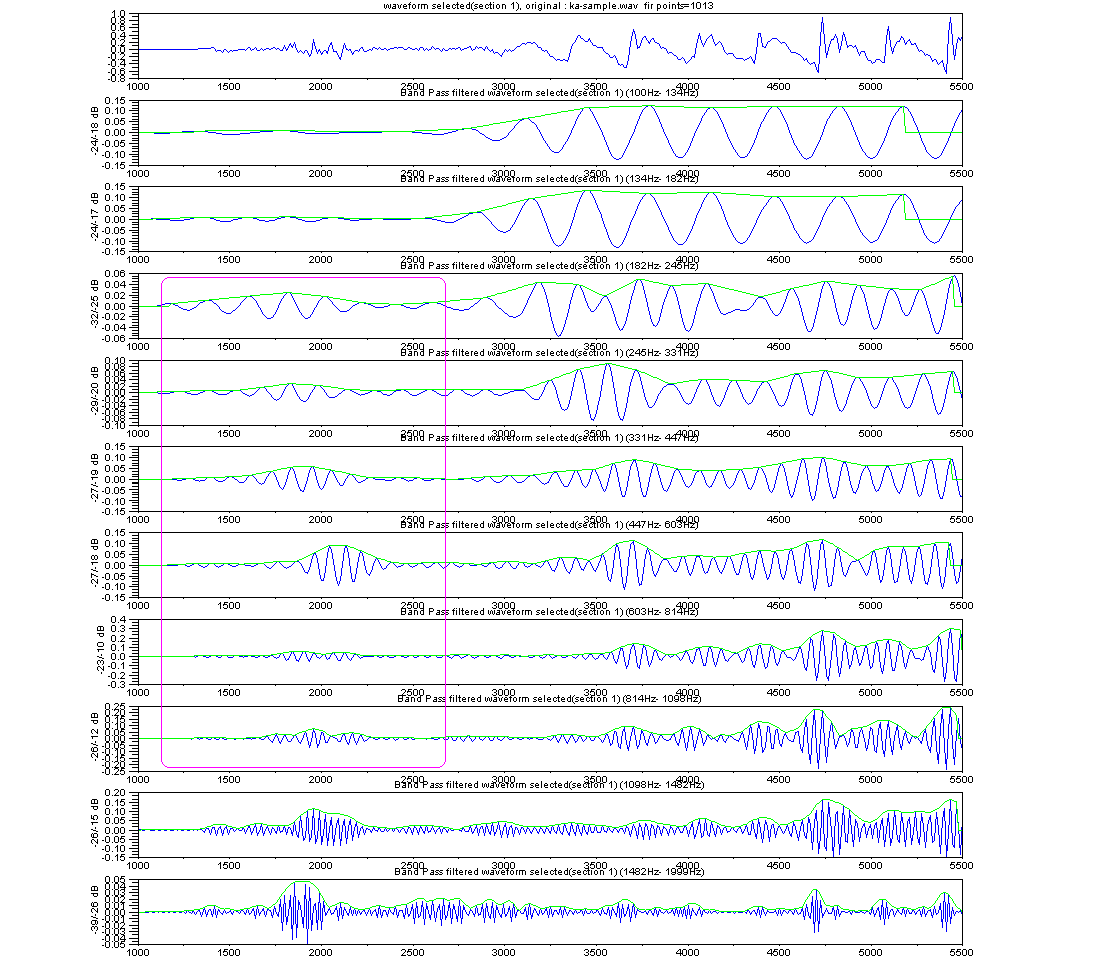
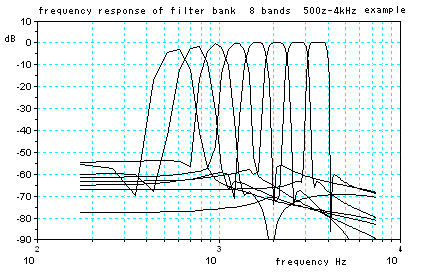
生する音の成分と、息を吹いて発生する乱流による音の成分の、2重構造になっている。(資料) それに対して、「た」の音のはじめは、口が閉じたところから行き成り息を吹きかけた成分のみが主な構成要素である。 右図の図の上の波形は、「か」の音の波形であるが、「か」の音のはじめの部分を低域カットフィルターをつ かって成分を抜いてやると、右図の下の波形のようになり、「た」の音の様に 聞こえるようになる。 乱流からの音はヒトの耳につきやすい音であるが、この種類の音の同定に周波数分析法では不足の感があるので、もっとよい分析法のアイデアが欲しいところで あ る。ちなみに、空洞音や乱流の波形はヒトによってかなり異なる。 無声音の部分、例えば、「か」「た」「さ」のはじめの部分に関しては、有声音に含まれる声門波のような基準となる同期信号が含まれていない。そこで、乱 流によって突然発生するバースト波 複数のバンドパスフィルターで構成されるフィルターバンクをとうして、相対的に見比べて、それぞれの波形の特徴がないかどうかを少し長い時間長 で観察してみることにした。右の6つの図は、どこに違いがあるかを見るために、「か」「た」「さ」の無声音部分について2人のヒトの波形を比較のために並 べたものである。 また別の例では、「さ」の音のはじめの部分を無くして短くすると「た」の音のように聞こえるようになる(右 図の一番下の波形)。このことから、「さ」の音は、口先に息を吹きかけて発生させている音が、ある時間の間 ”安定して持続していること” に意味が あることが推測される。この部分が確率論的な認識をするためそれなりの時間間隔が要求されると、考えることができるかもしれない。 話題は変わるが、過去の研究から、濁音と非濁音の差は、声門からの信号との関係に時間差があることが知られている。 更に、は行の音(「は」「ひ」「ふ」「へ」「ほ」)のように、後続する母音の特徴を子音の部分に内在 しているものもある。たとえば、「は」のはじめの部分と「ほ」のはじめの部分は違う つくりになっているように。 |
 フィルターバンクから出力された波形を比較したもの フィルターの分割数は8 無声音部分の波形 図をクリックすると拡大図になります
 |
|
||
 |
| 何十年前に比べれは、機械の信号処理能力は発達し、音声の信号を大量に確率論的
に扱うことは得意?になった。確率データに構
造を結びつけることによって、それが何であるかを裏付けできる認識マシーンができないであろうか? 元の信号の分析解像度が同じならば、スペクトルを使おうとケプストラムを使おうと、それ以外を使おうと、本質的に分布群の構成は行き着くところは同じよ うになる可能性がある思う。 子音は(発声器官の)特異な状態から母音状態への変遷過程であり、構造上の変移過程であり、構造上の運動が無駄な動きを避けることにより存在できる種類 が特定されるのではないだろうか。つまり、分布上の変遷道筋も、構造不変に保つ変換が存在し、かつ、発声器官の特異な状態による種別から子音の数は有限の 数に限られるのではないだろうか。 |
 |
| Open Directory プロジェクトの ミラー(2017年3月時点) |
W3CによるHTMLの Web文法チェッカー |
|
このWEBサ
イトを閲覧して頂きありがとうございました。
|
since 2005.7.17 |


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}